/var/folders/rj/c4rjx52d217gsm3ccfx5q20r0000gr/T/ipykernel_90254/3387420824.py:93: DeprecationWarning:
*scattermapbox* is deprecated! Use *scattermap* instead. Learn more at: https://plotly.com/python/mapbox-to-maplibre/
Identifying Compounds
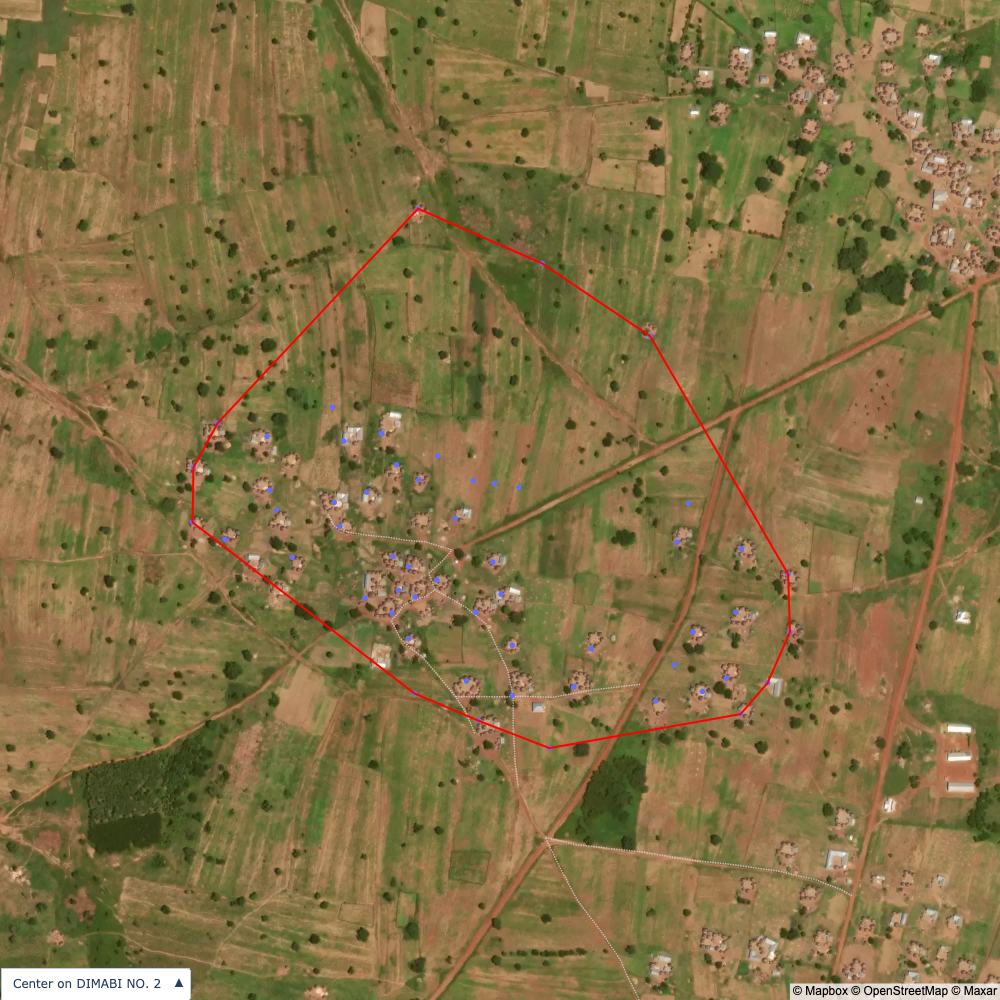
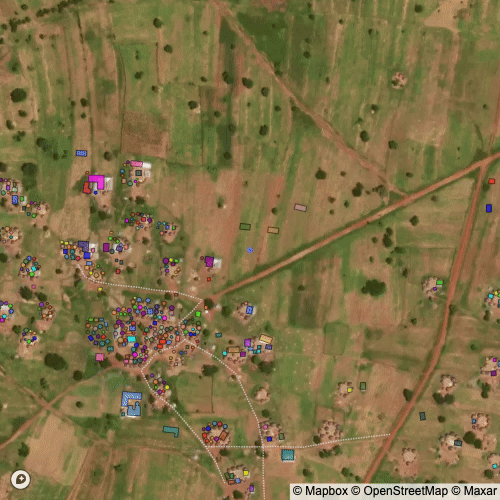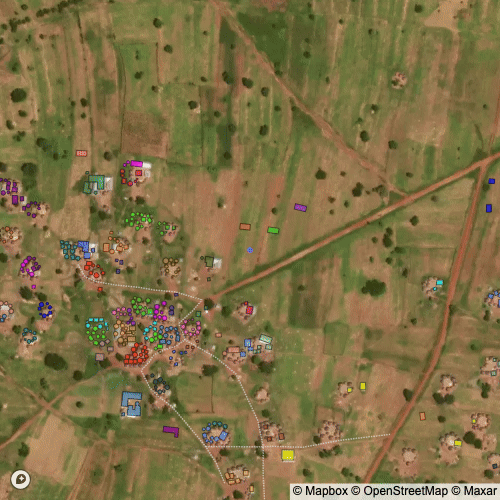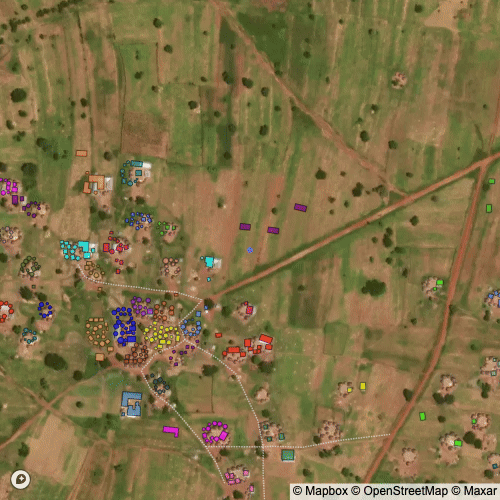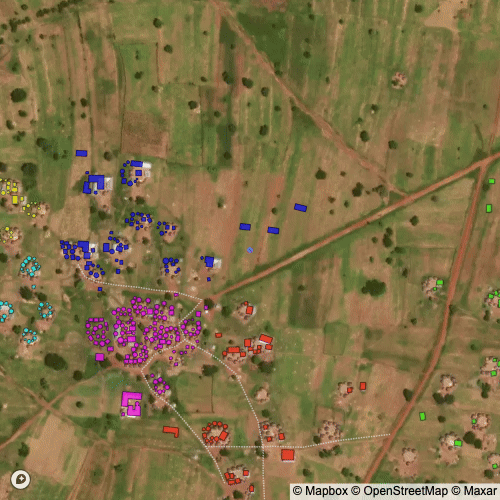
Finally, we can apply various clustering algorithms to group structures into compounds. However, there is no obvious threshold for what is a compound and what isn’t. Visually, the cluster in the middle from DIMABI NO. 2 is difficult to identify as a single or multiple compounds or where the boundaries for the compounds would be.
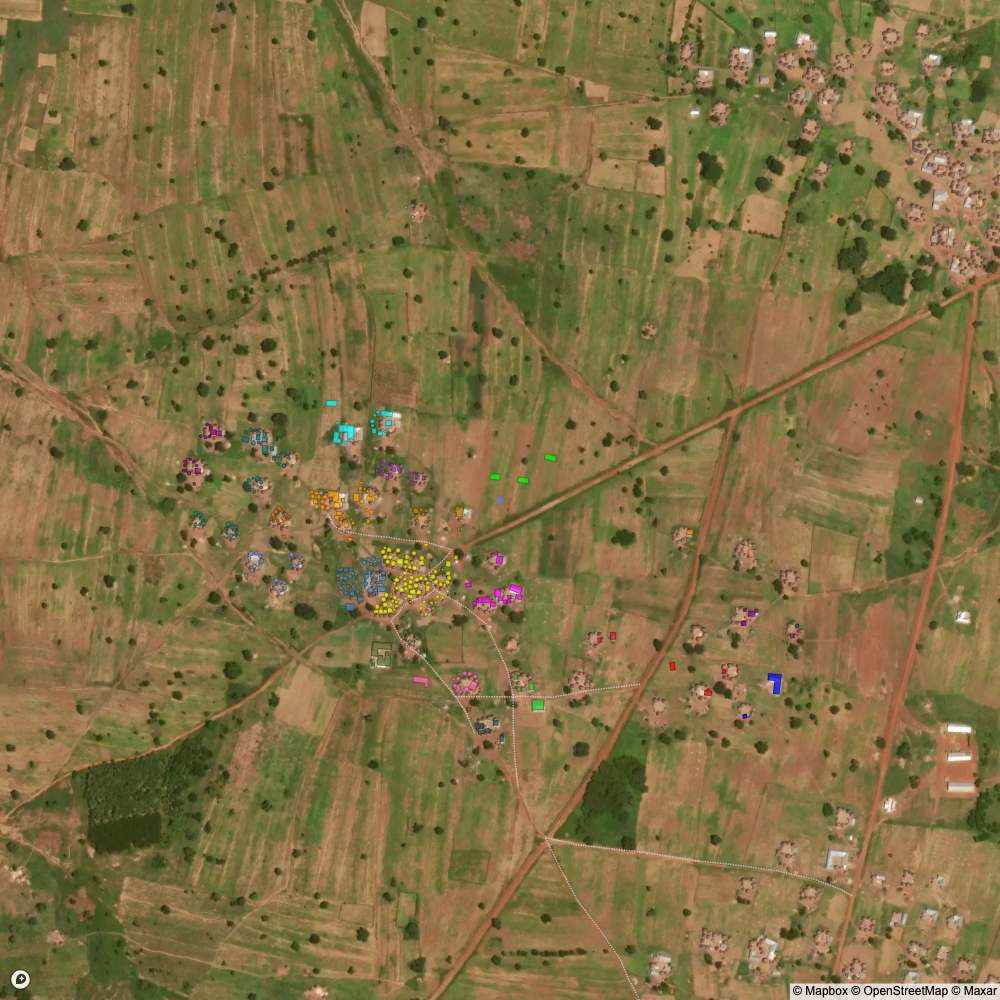
I used a clustering with a distance parameter set by “eye” (i.e. arbitrarily) to define what a compound should be. The result is visible below and closely matches what I would have done manually had I grouped compounds by hand.
Code
```{python}# | warning: false# Corresponds to 5m (from Claude)###### An eps of 0.00005 degrees would translate to approximately:###### 0.00005 × 111,320 meters ≈ 5.57 meters (about 18.3 feet)dimabi_building_gdf.loc[:, f"h_labels"] = cluster.cluster_hierarchical_average( dimabi_building_gdf, distance_threshold=0.00054)```
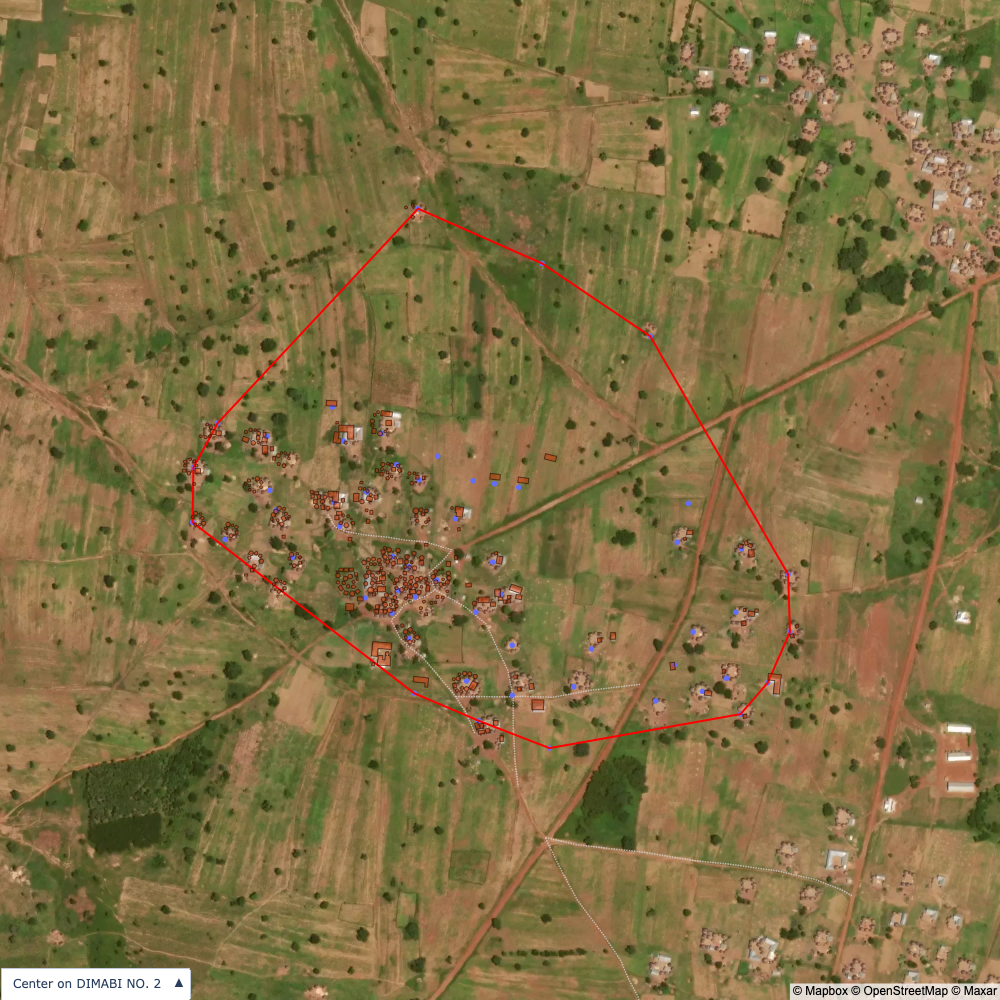
I do not know how up-to date / accurate building data is. It seems to align with the satellite imagery fairly well but I don’t know enough about the context to make a judgement
Caution
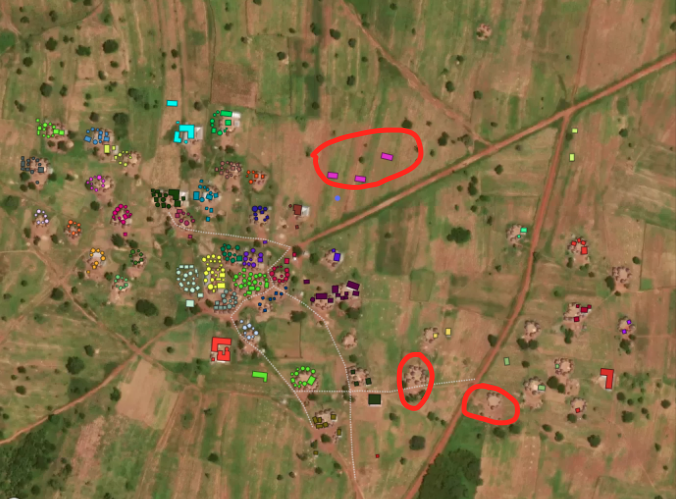
Note the mismatch of the building data and satellite images. They contradict each other and it’s not clear that it would be right to assume one or the other is correct
data inconsistencies
Clustering Algorithm
I use agglomerative clustering to group buildings and structures into compounds. The algorithm works by joining individual points (in our case, points are buildings) into clusters.
agglomerative clustering
In our case, unlike the visualization, we terminate the algorithm early once the distance between clusters exceeds some threshold. That is, we would stop at Step 2 or Step 3 — depending on how we set the distance threshold.
I currently have this set at 0.0007 after some trial-and-error but it is somewhat arbitrary. We don’t have any labelled training data to pick the best parameter here nor is it immediately obvious that the parameter should be identical across communities.
Tip
0.0007 degrees is roughly about 78m
Below is a visualization of the clustering algorithm at different distance thresholds; it can also help explain how the clustering works in our context