```{python}#| label: shock-mh-regressions-nonrelgious#| output: asissg = Stargazer(models)sg.title('Impact of non-relgious shocks on mental health at baseline')sg.custom_columns(mh_full_vars, [1] * len(mh_full_vars))sg.show_model_numbers(False)sg```
Impact of non-relgious shocks on mental health at baseline
phq8
gad7
pss10
pswq16
diener5
cantril_total
Intercept
8.065***
7.244***
19.325***
51.251***
20.729***
11.206***
(0.150)
(0.138)
(0.152)
(0.236)
(0.225)
(0.129)
shock_nonreligious
-0.323*
-0.207
0.350*
-0.038
-0.251
-0.041
(0.190)
(0.174)
(0.192)
(0.298)
(0.284)
(0.163)
Observations
2272
2272
2272
2272
2272
2272
R2
0.001
0.001
0.001
0.000
0.000
0.000
Adjusted R2
0.001
0.000
0.001
-0.000
-0.000
-0.000
Residual Std. Error
4.380 (df=2270)
4.017 (df=2270)
4.424 (df=2270)
6.868 (df=2270)
6.543 (df=2270)
3.768 (df=2270)
F Statistic
2.886* (df=1; 2270)
1.406 (df=1; 2270)
3.333* (df=1; 2270)
0.016 (df=1; 2270)
0.780 (df=1; 2270)
0.063 (df=1; 2270)
Note:
*p<0.1; **p<0.05; ***p<0.01
Code
```{python}#| label: shock-mh-regressions-any#| output: asissg = Stargazer(models_any)sg.title('Impact of any shock on mental health at baseline')sg.custom_columns(mh_full_vars, [1] * len(mh_full_vars))sg.show_model_numbers(False)sg```
Impact of any shock on mental health at baseline
phq8
gad7
pss10
pswq16
diener5
cantril_total
Intercept
9.106***
8.000***
19.663***
51.606***
21.482***
12.216***
(0.259)
(0.238)
(0.264)
(0.409)
(0.389)
(0.223)
shock_any
-1.420***
-1.011***
-0.135
-0.433
-1.039**
-1.183***
(0.277)
(0.255)
(0.282)
(0.437)
(0.416)
(0.238)
Observations
2272
2272
2272
2272
2272
2272
R2
0.011
0.007
0.000
0.000
0.003
0.011
Adjusted R2
0.011
0.006
-0.000
-0.000
0.002
0.010
Residual Std. Error
4.358 (df=2270)
4.005 (df=2270)
4.427 (df=2270)
6.867 (df=2270)
6.535 (df=2270)
3.748 (df=2270)
F Statistic
26.226*** (df=1; 2270)
15.743*** (df=1; 2270)
0.231 (df=1; 2270)
0.982 (df=1; 2270)
6.244** (df=1; 2270)
24.592*** (df=1; 2270)
Note:
*p<0.1; **p<0.05; ***p<0.01
Code
```{python}#| label: shock-mh-regressions-religious#| output: asissg = Stargazer(models_religious)sg.title('Impact of religious shocks on mental health at baseline')sg.custom_columns(mh_full_vars, [1] * len(mh_full_vars))sg.show_model_numbers(False)sg```
Impact of religious shocks on mental health at baseline
phq8
gad7
pss10
pswq16
diener5
cantril_total
Intercept
8.178***
7.269***
19.615***
51.774***
19.858***
12.058***
(0.173)
(0.159)
(0.175)
(0.271)
(0.258)
(0.147)
shock_religious_event
-0.439**
-0.216
-0.099
-0.762**
0.995***
-1.223***
(0.204)
(0.187)
(0.206)
(0.320)
(0.304)
(0.174)
Observations
2272
2272
2272
2272
2272
2272
R2
0.002
0.001
0.000
0.003
0.005
0.021
Adjusted R2
0.002
0.000
-0.000
0.002
0.004
0.021
Residual Std. Error
4.378 (df=2270)
4.017 (df=2270)
4.427 (df=2270)
6.860 (df=2270)
6.529 (df=2270)
3.728 (df=2270)
F Statistic
4.629** (df=1; 2270)
1.333 (df=1; 2270)
0.229 (df=1; 2270)
5.691** (df=1; 2270)
10.700*** (df=1; 2270)
49.547*** (df=1; 2270)
Note:
*p<0.1; **p<0.05; ***p<0.01
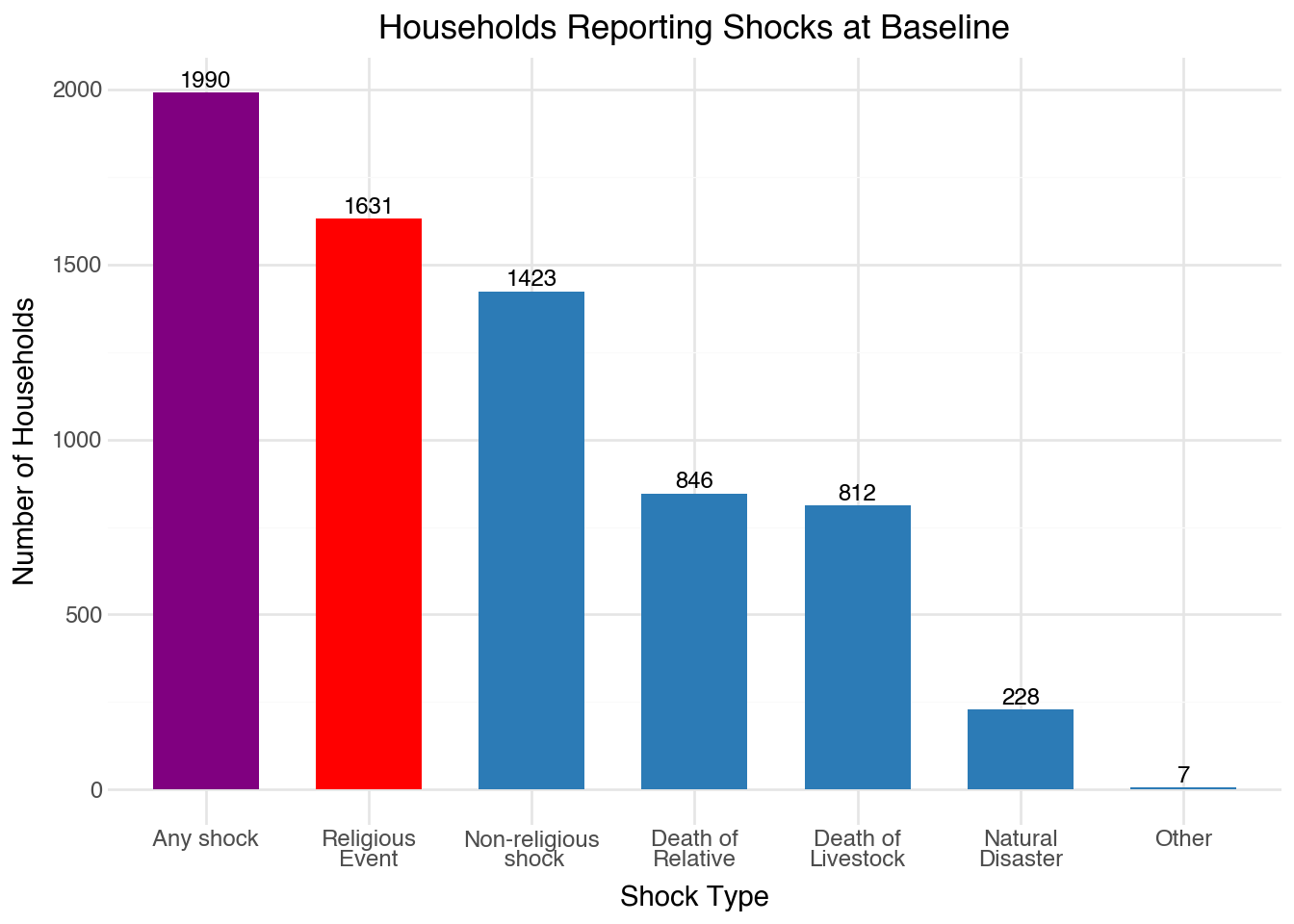
Strange, the cantril moves in its own direction
Religious event good but also other shocks good? (noisy though)
We do have the sample size to talk about shocks (nearly 50-50 split in who experiences it)
Dynamics and Recovery
Code
```{python}#| label: shock-period-regressions#| warning: falsemental_health_vars = ['phq2', 'gad2', 'pss4', 'pswq3']mh_all = mental_health.copy()[['hh_id', 'period', 'treatment'] + mental_health_vars]dynamic_data = mh_all.merge(in_person[['hh_id','shock_nonreligious', 'shock_religious_event', 'shock_any']], on='hh_id', how='left')model_store = {}for period in range(0, 7): model_store[period] = {} model_store[period]['nonreligious'] = {} for var in mental_health_vars: model = smf.ols(f'{var} ~ shock_nonreligious + C(treatment) ', data=dynamic_data[dynamic_data['period'] == period]).fit() model_store[period]['nonreligious'][var] = model model_store[period]['religious'] = {} for var in mental_health_vars: model = smf.ols(f'{var} ~ shock_religious_event + C(treatment) ', data=dynamic_data[dynamic_data['period'] == period]).fit() model_store[period]['religious'][var] = model model_store[period]['any'] = {} for var in mental_health_vars: model = smf.ols(f'{var} ~ shock_any + C(treatment) ', data=dynamic_data[dynamic_data['period'] == period]).fit() model_store[period]['any'][var] = model# Extract tuple of (coef, se) for shock variable across periods and outcomesresults_store = []for period in model_store.keys(): for shock_type in model_store[period].keys(): for outcome in model_store[period][shock_type].keys(): model = model_store[period][shock_type][outcome] coef = model.params[4] # Assuming shock variable is the first after intercept se = model.bse[4] results_store.append({ 'period': period, 'shock_type': shock_type, 'outcome': outcome, 'coef': coef, 'se': se, })results_clean = pd.DataFrame(results_store) results_clean['period'] = results_clean['period'].astype(int)results_clean['coef'] = results_clean['coef'].astype(float)results_clean['se'] = results_clean['se'].astype(float)ojs_define(data=results_clean.to_dict(orient='records')) ```
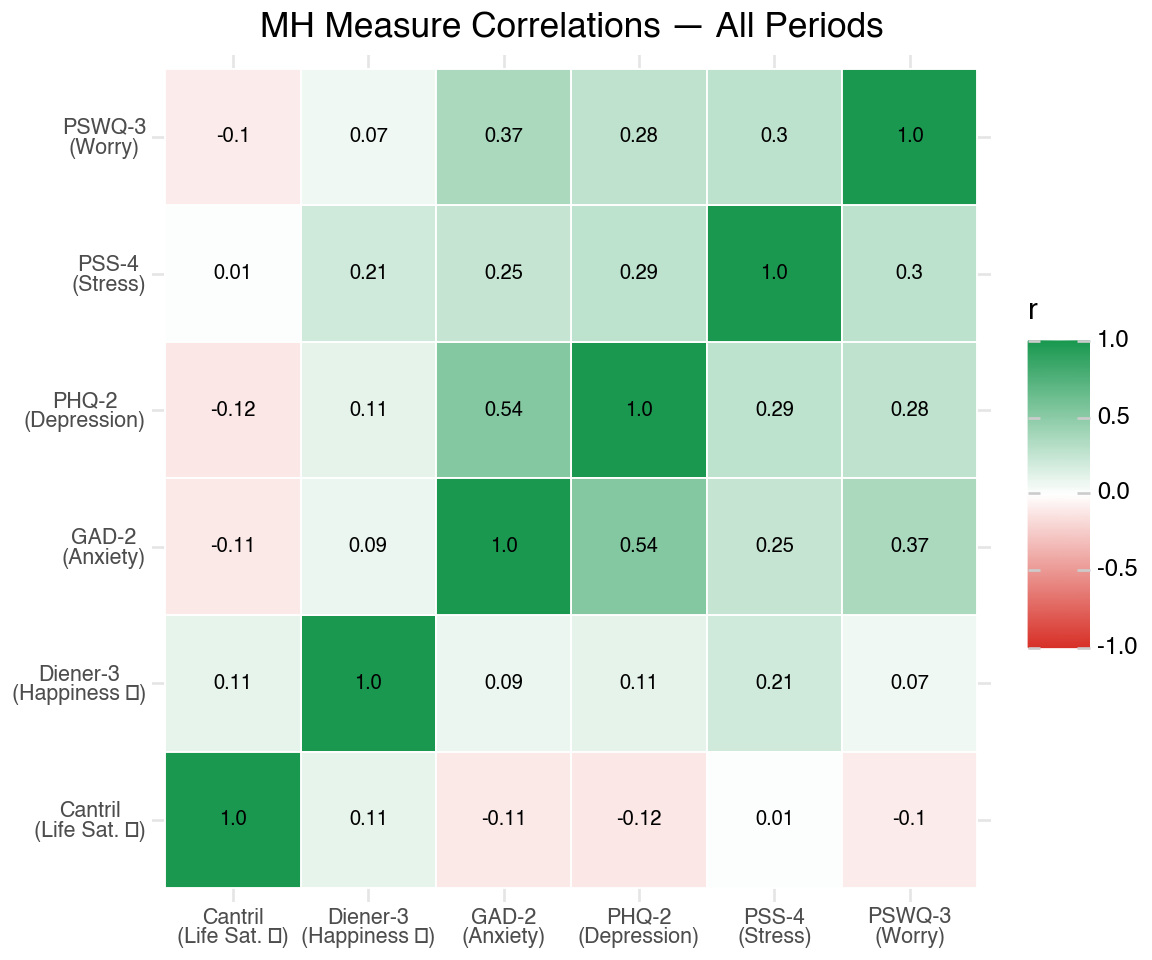
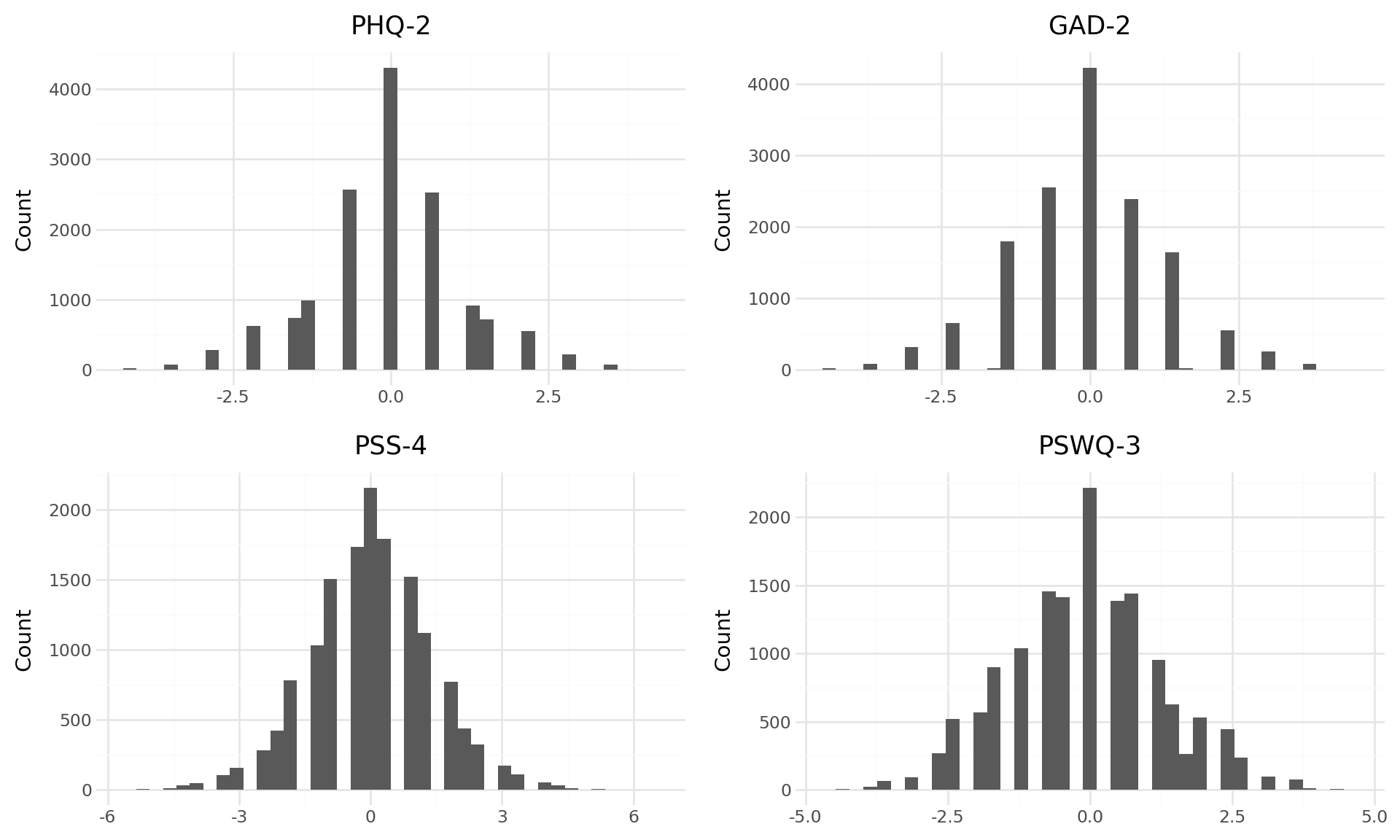
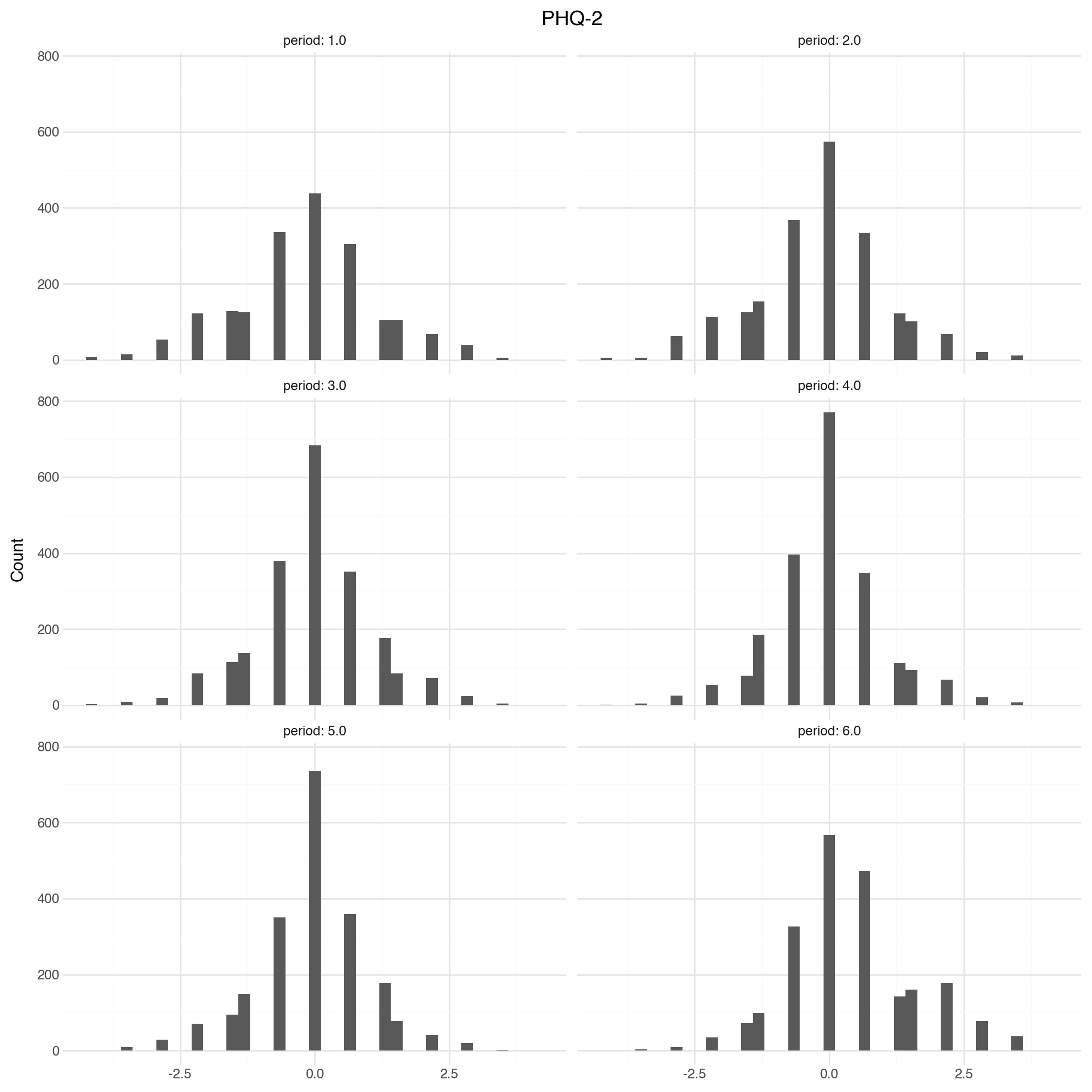
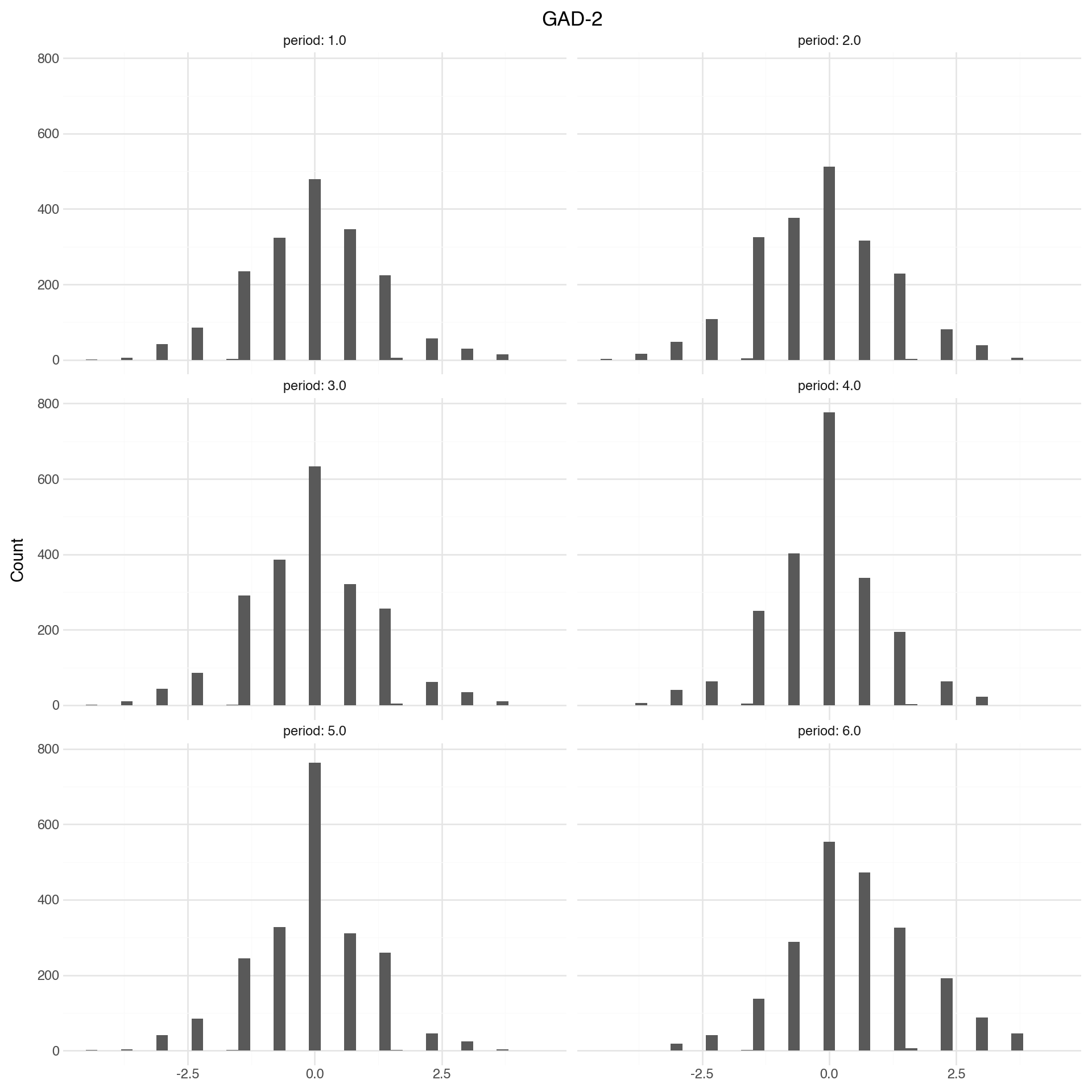
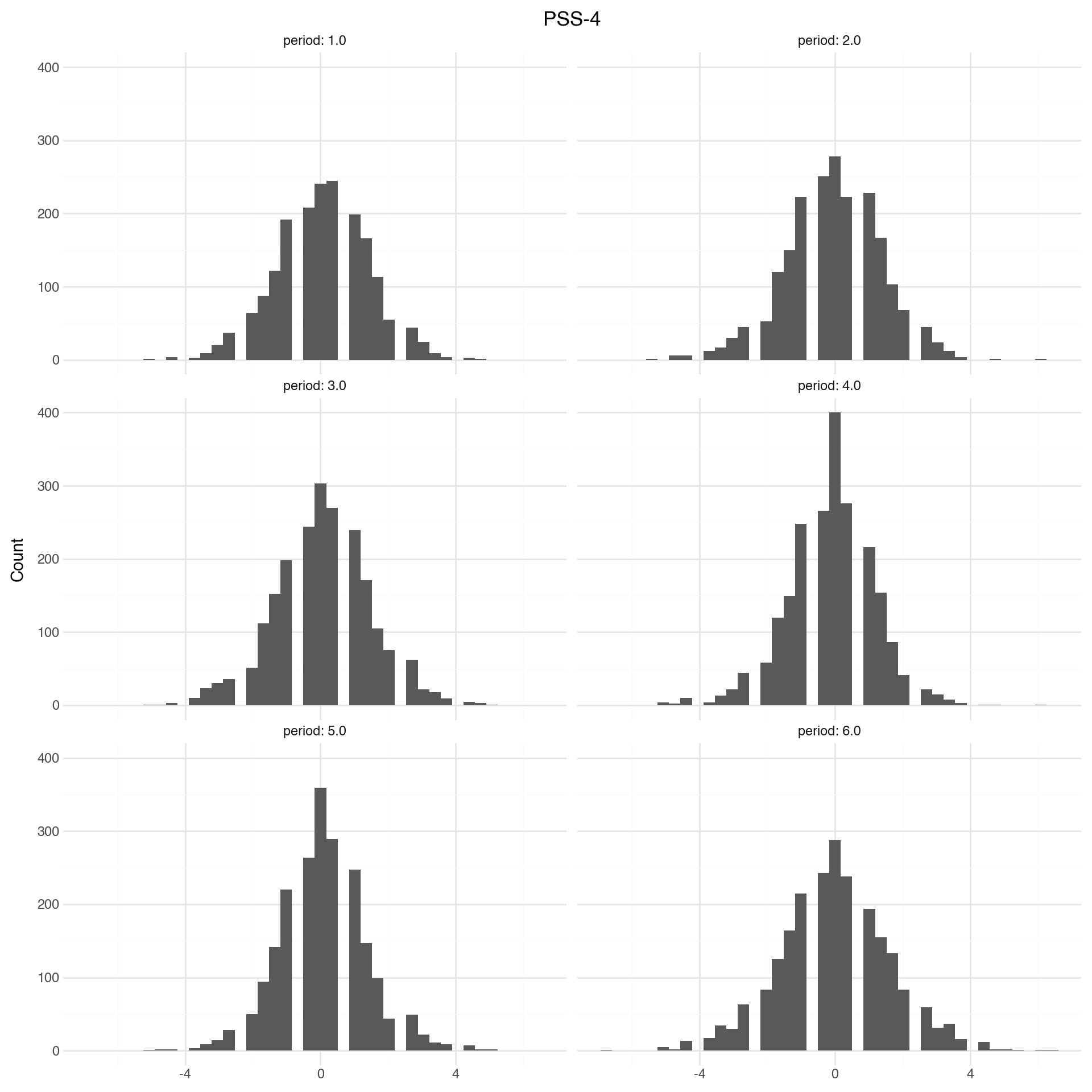
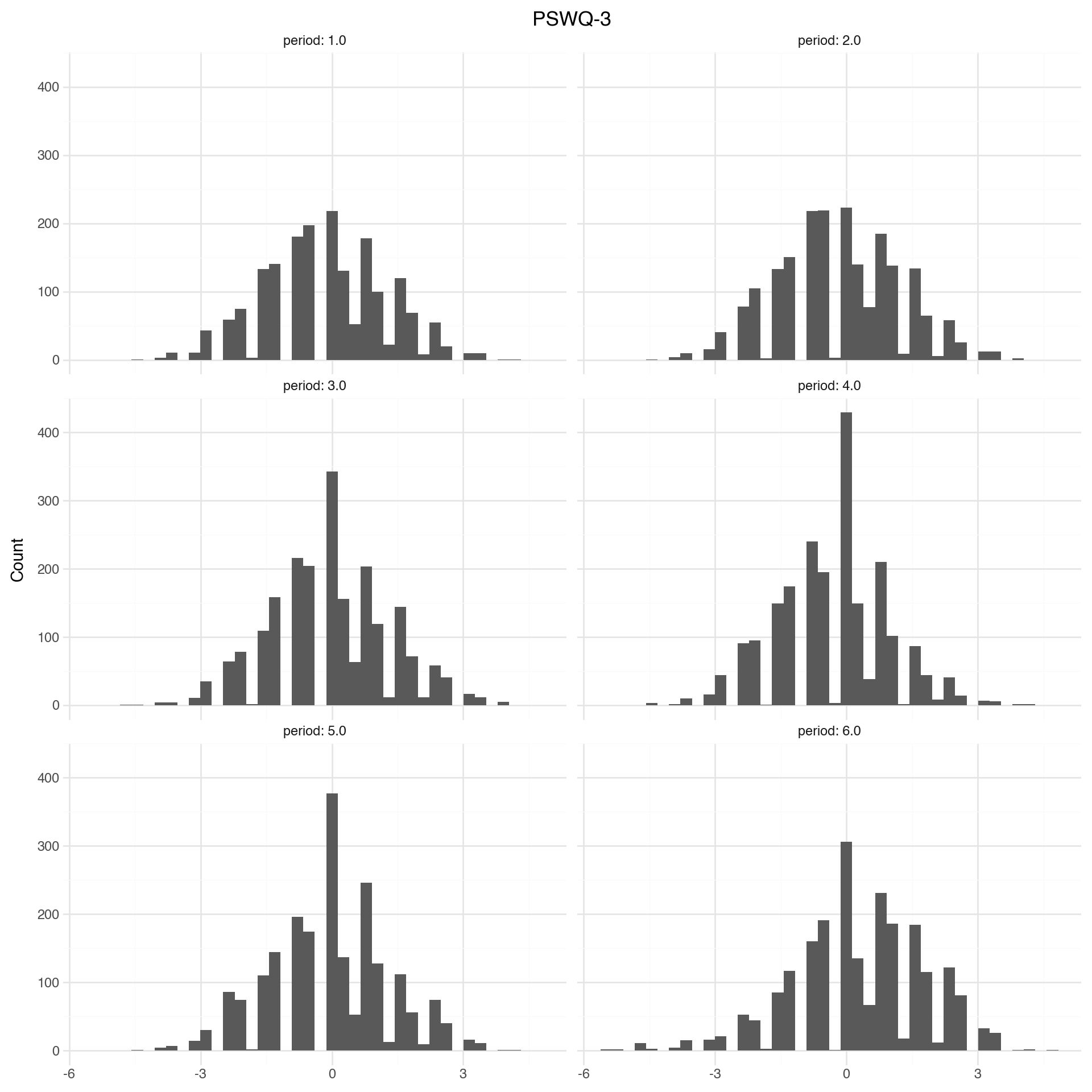
Measurements are remarkably stable. PHQ and GAD are a lot more stable than the stress and worry measures.
For the main study, we should consider using the other two measures. This + the correlations not necessarily being super high suggests there is a signal in the different measures
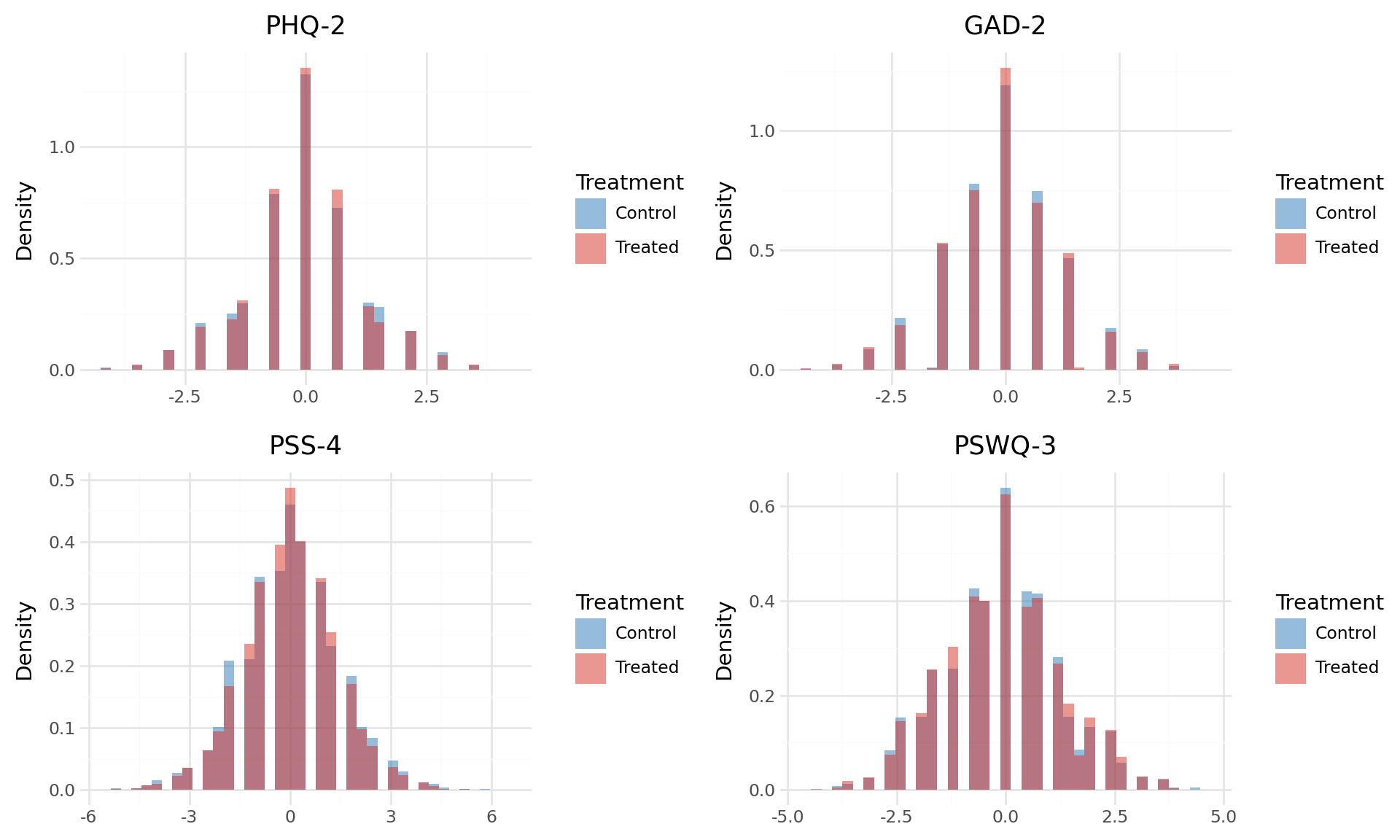
Note
The figures and tables below show how mental health is changing over time. Change is measured as difference in z-scores. Z-scores are computed relative to baseline distribution