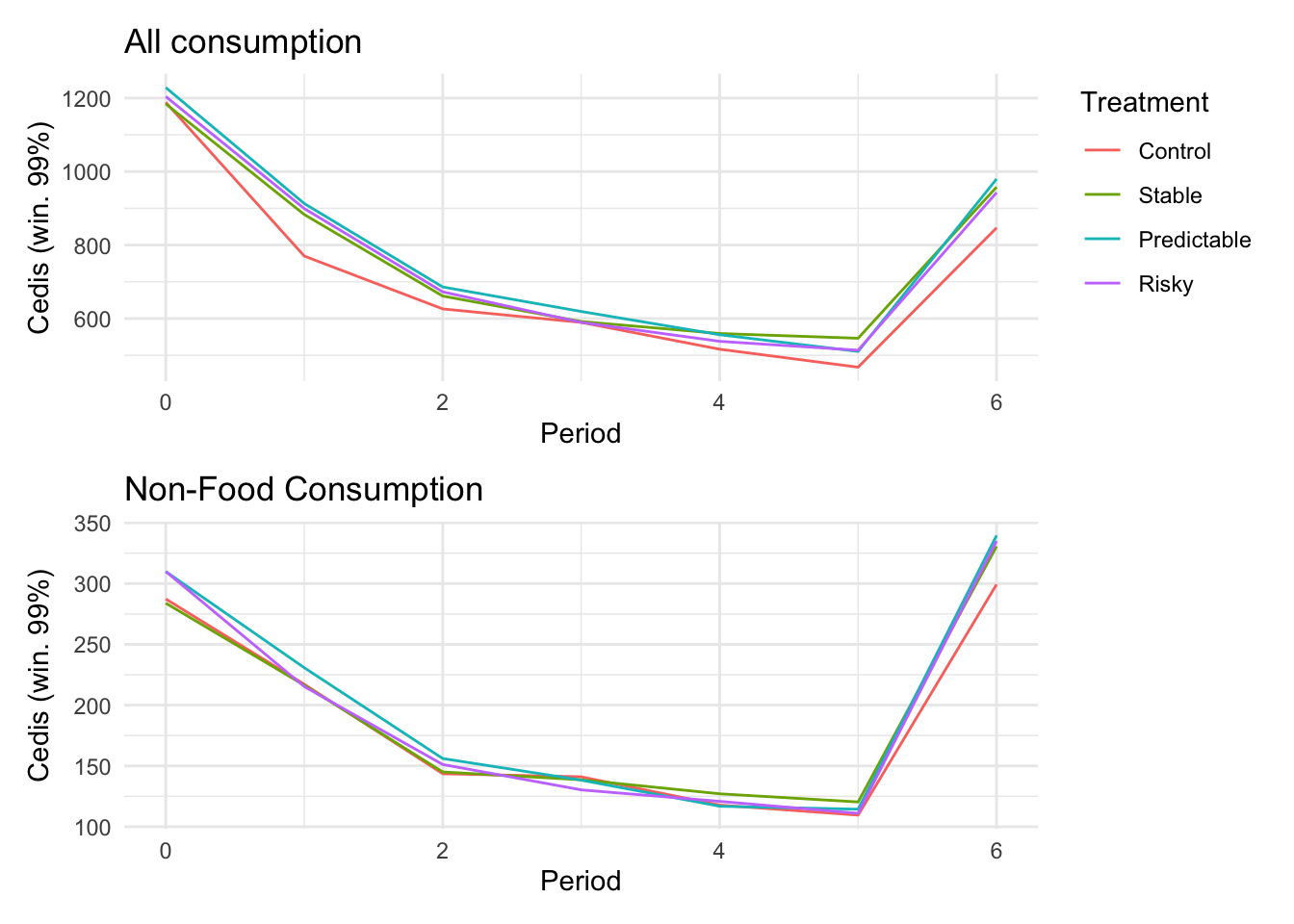
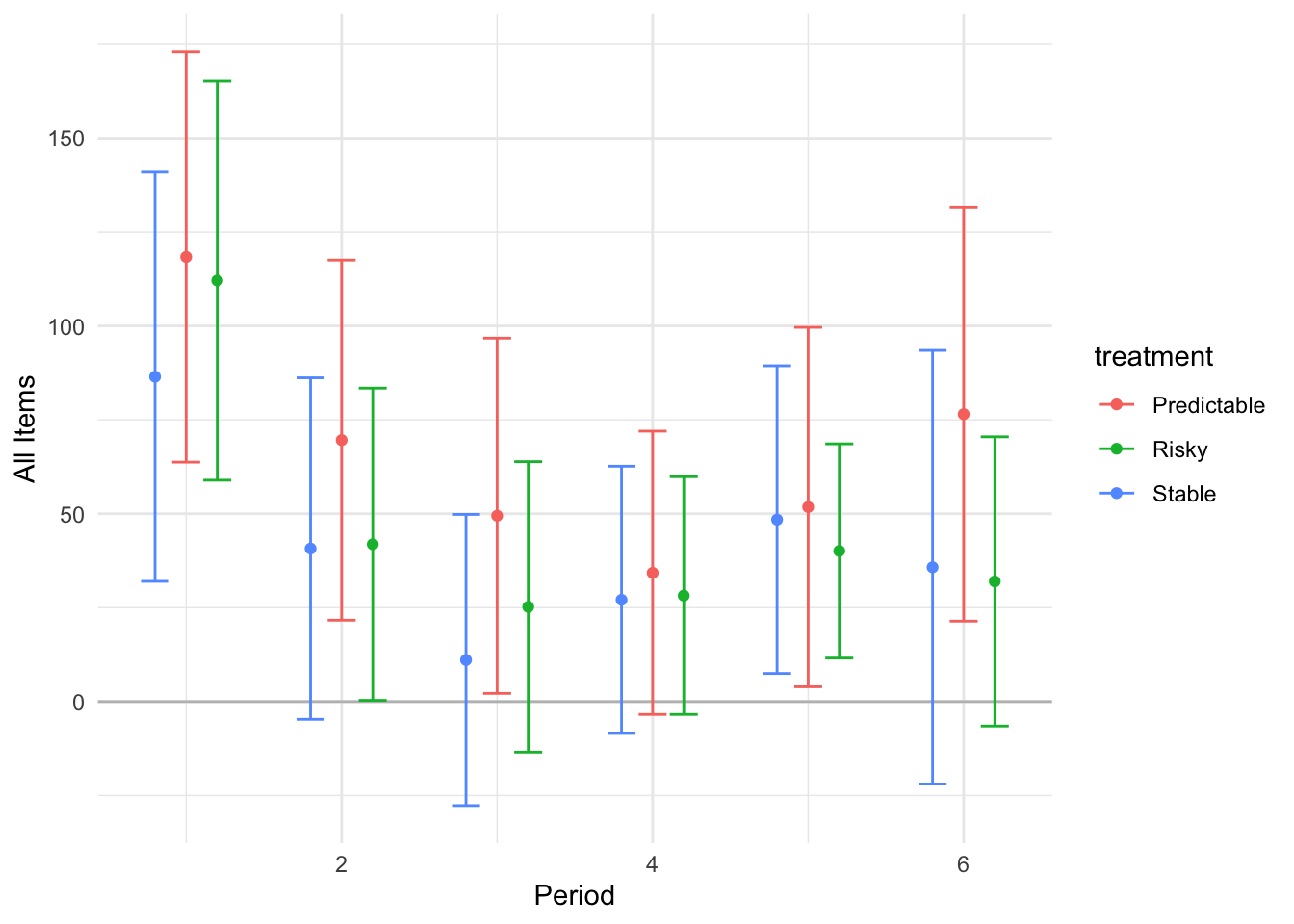
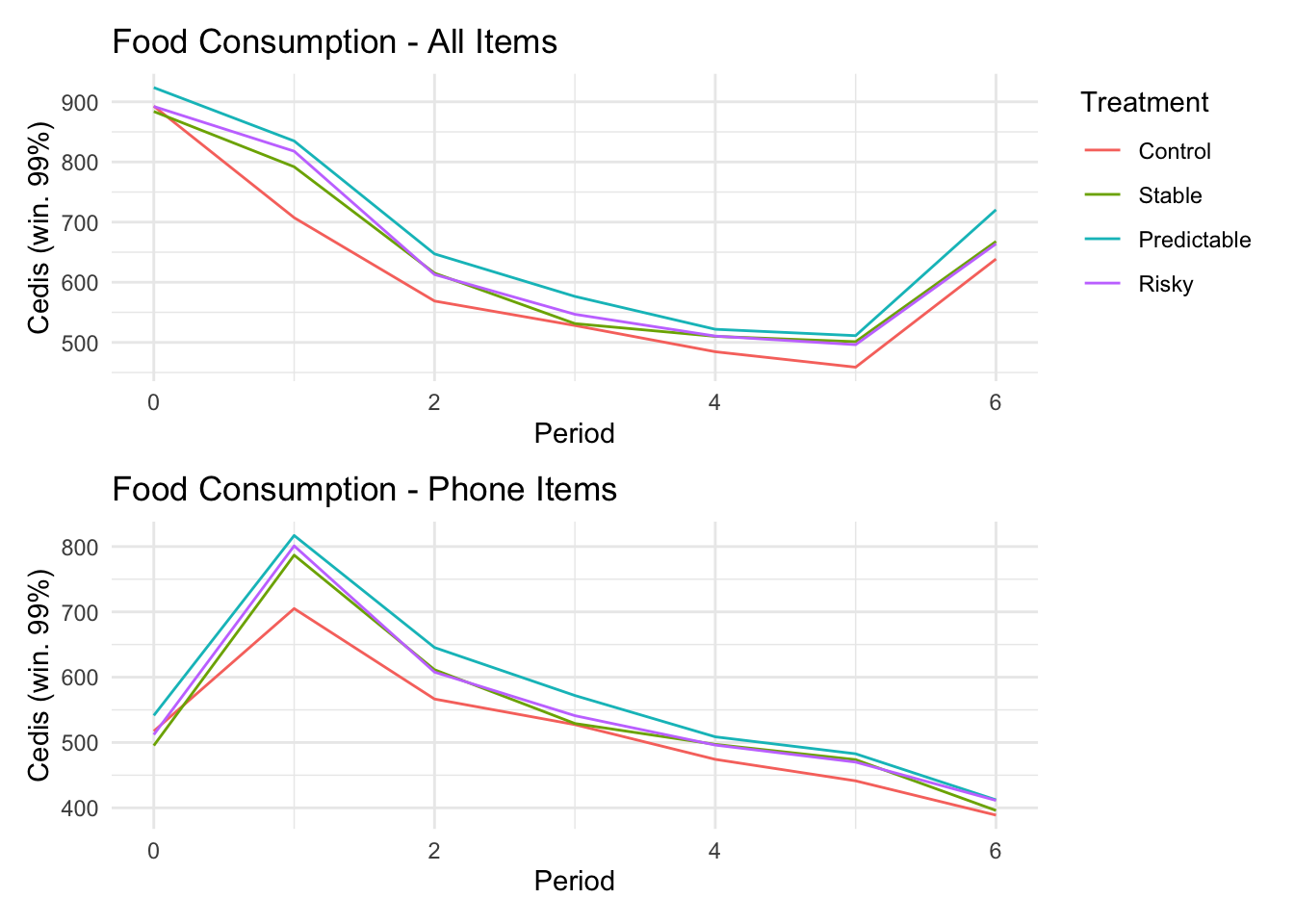
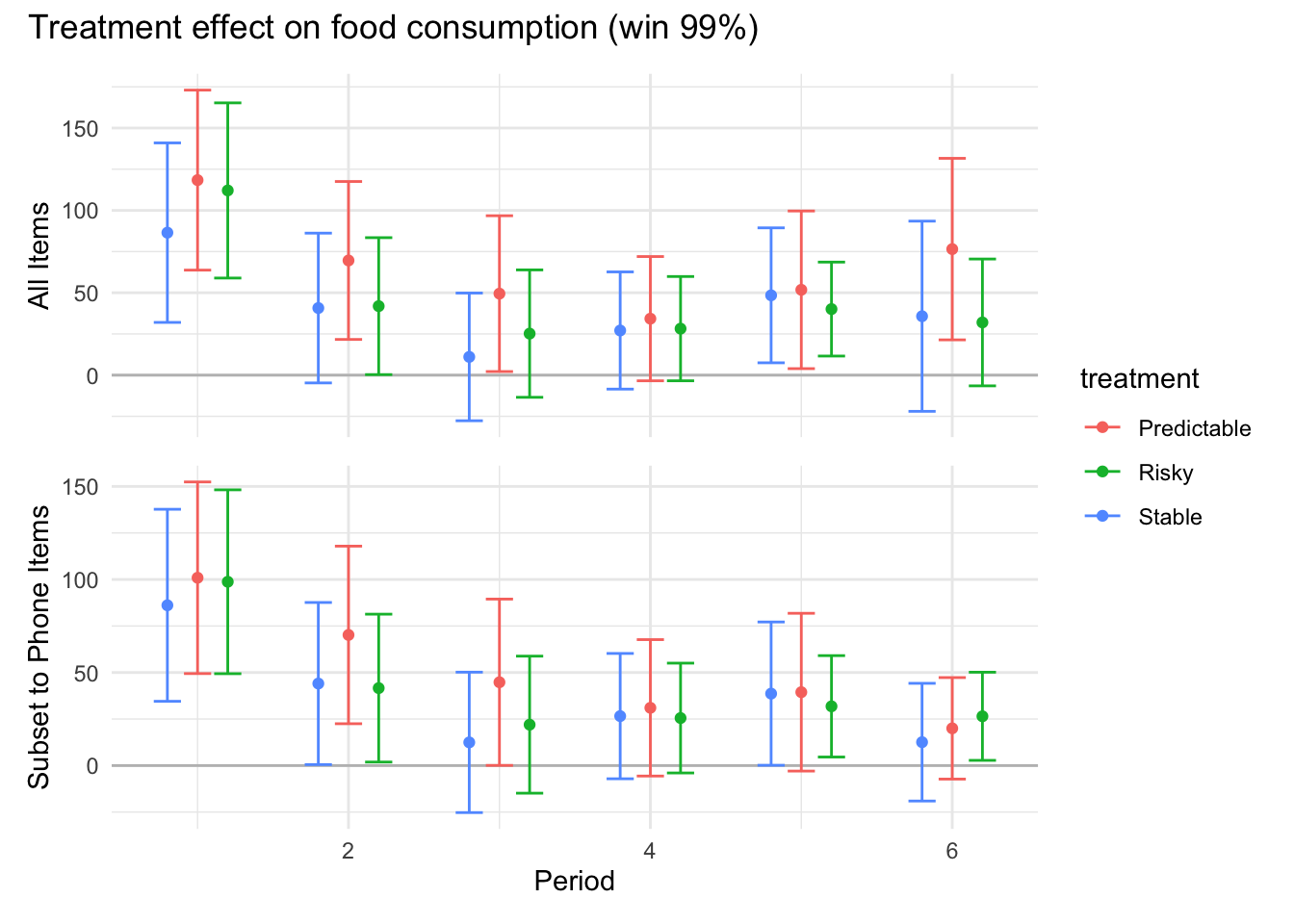
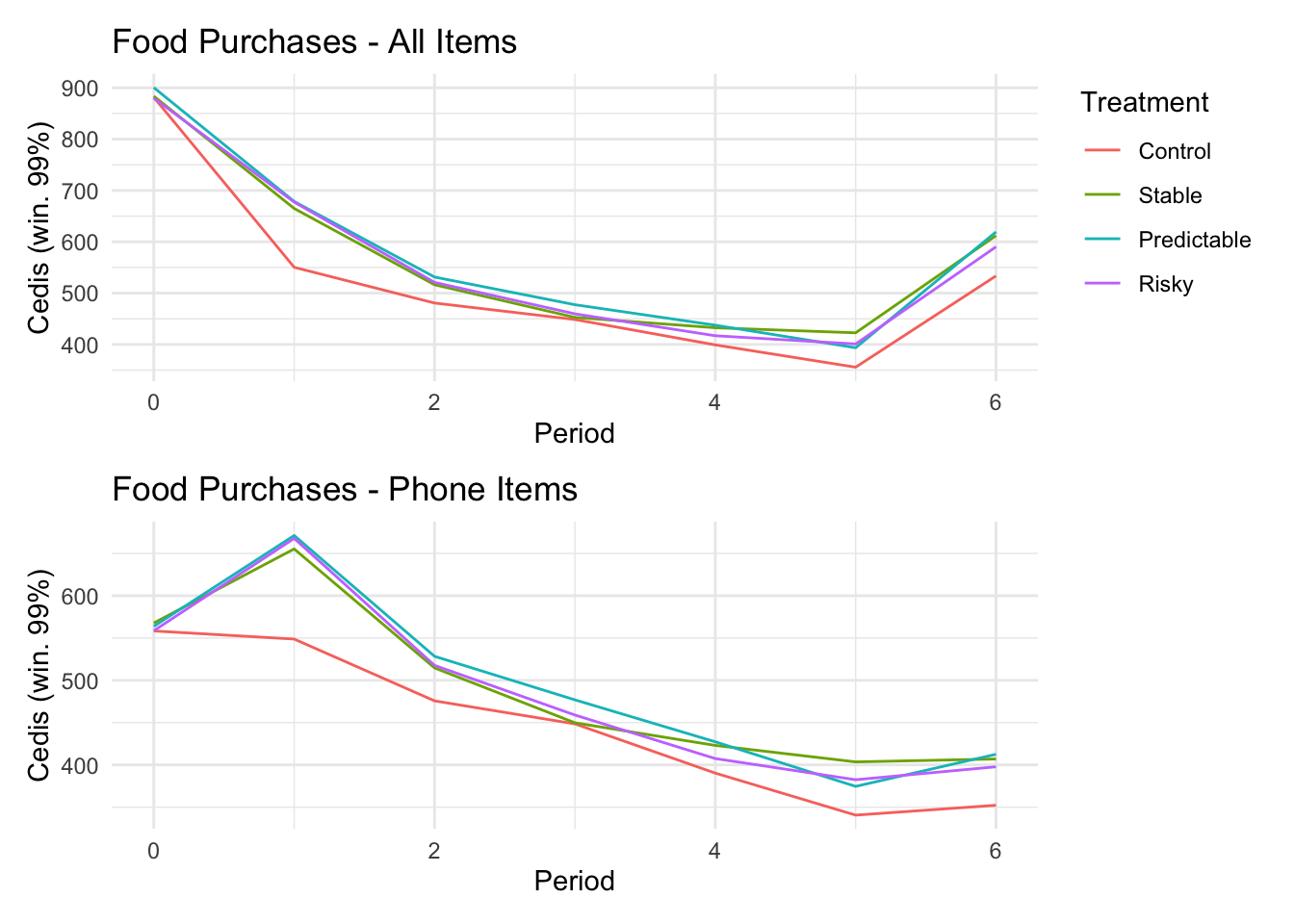
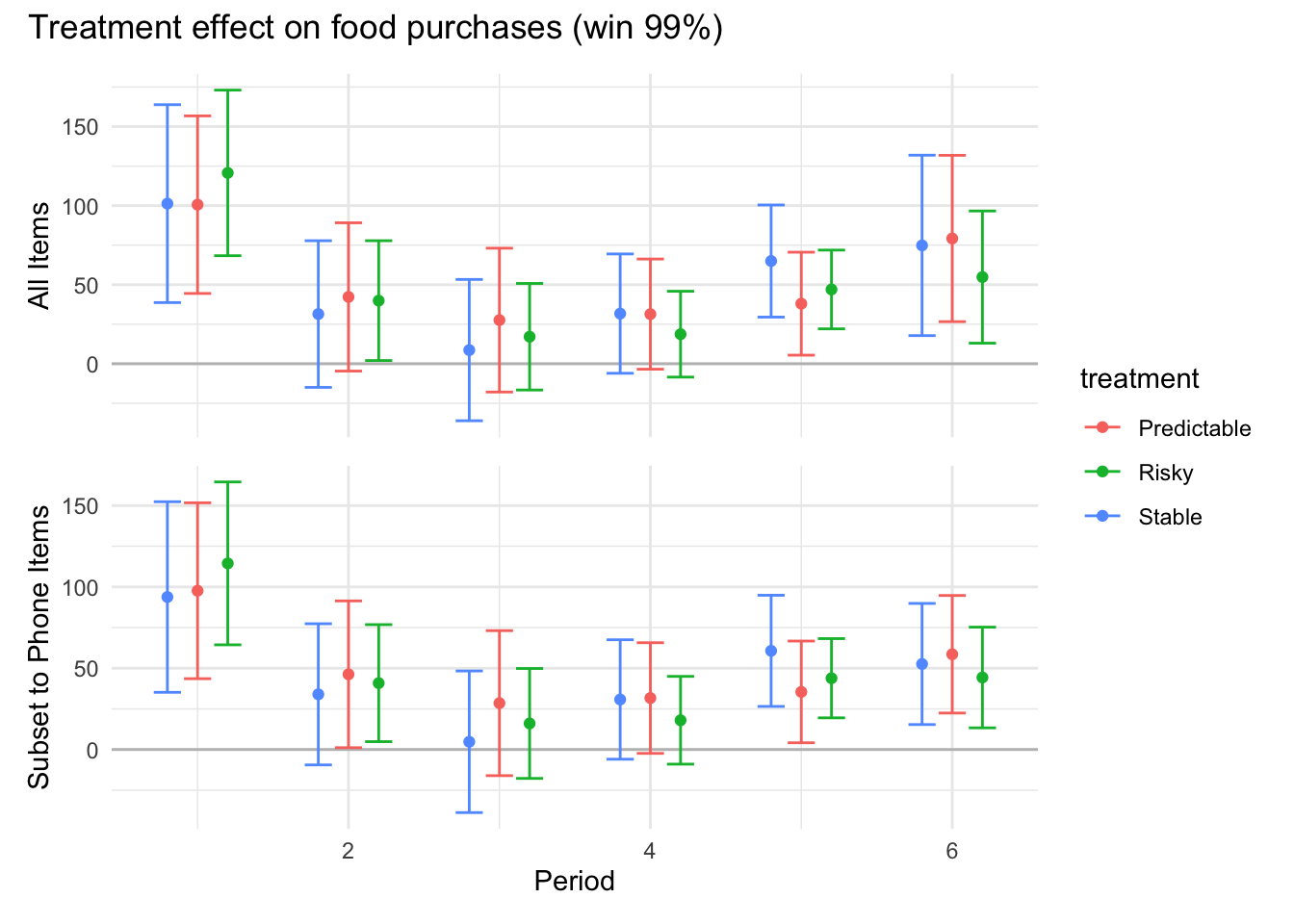
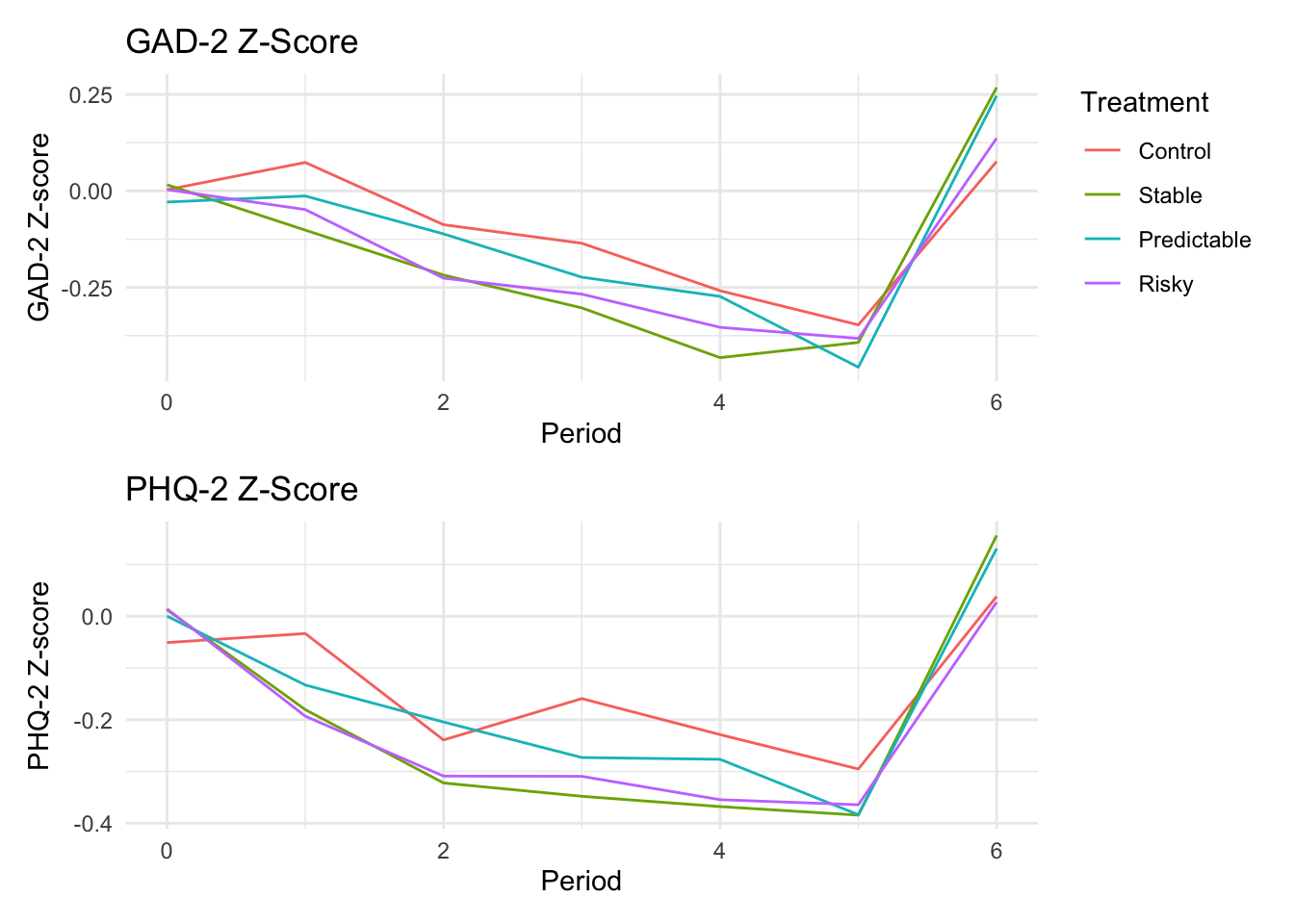
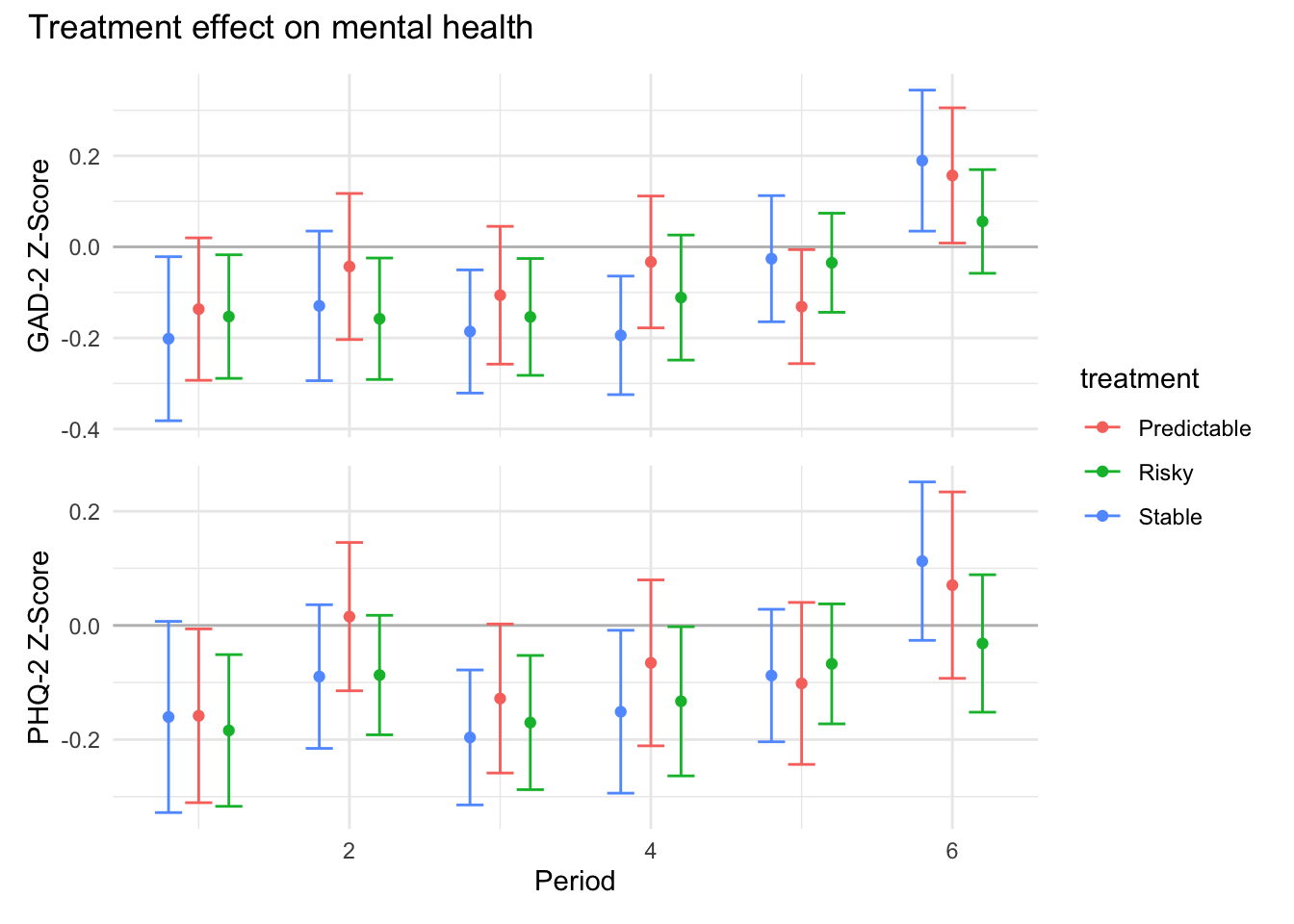
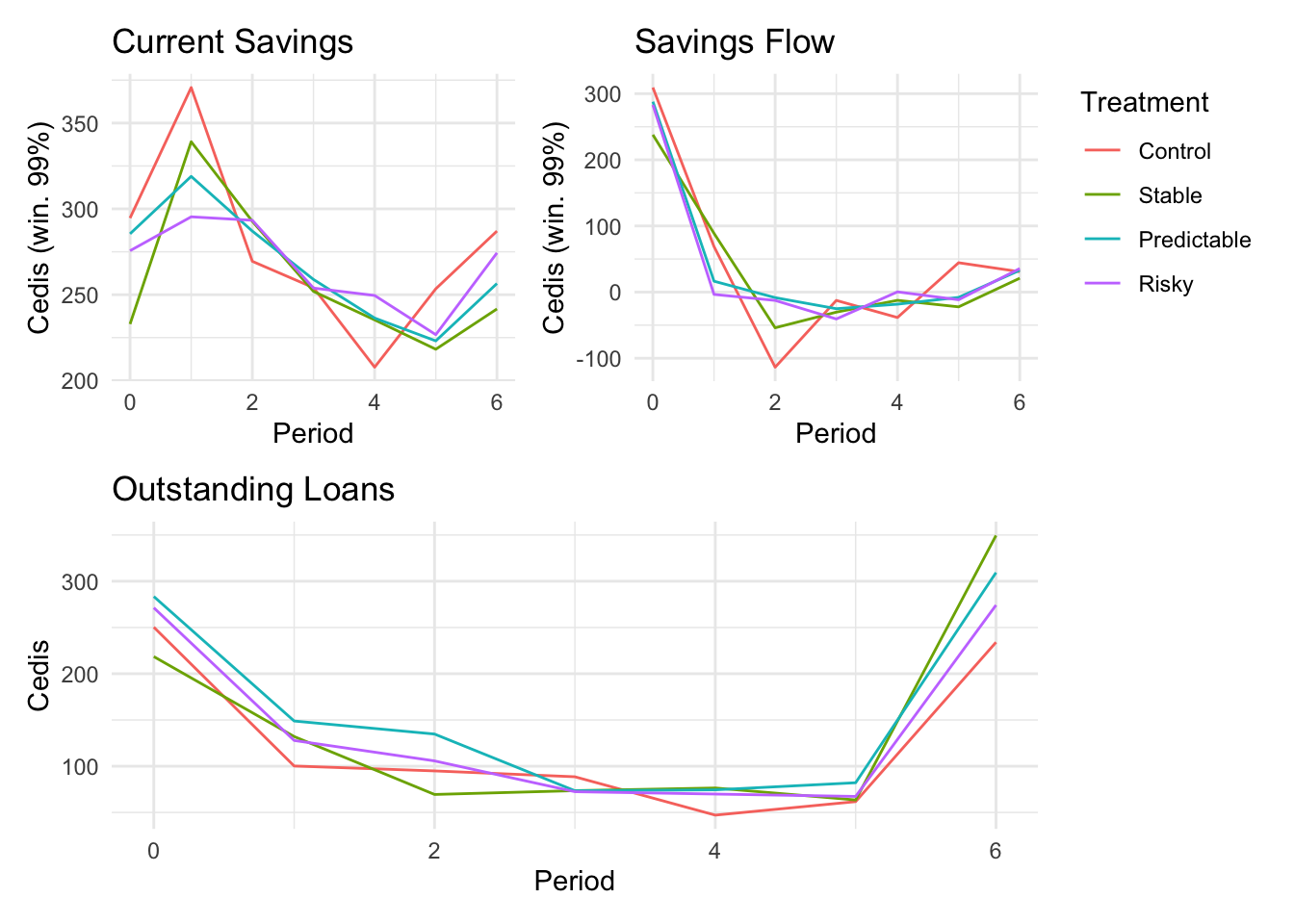
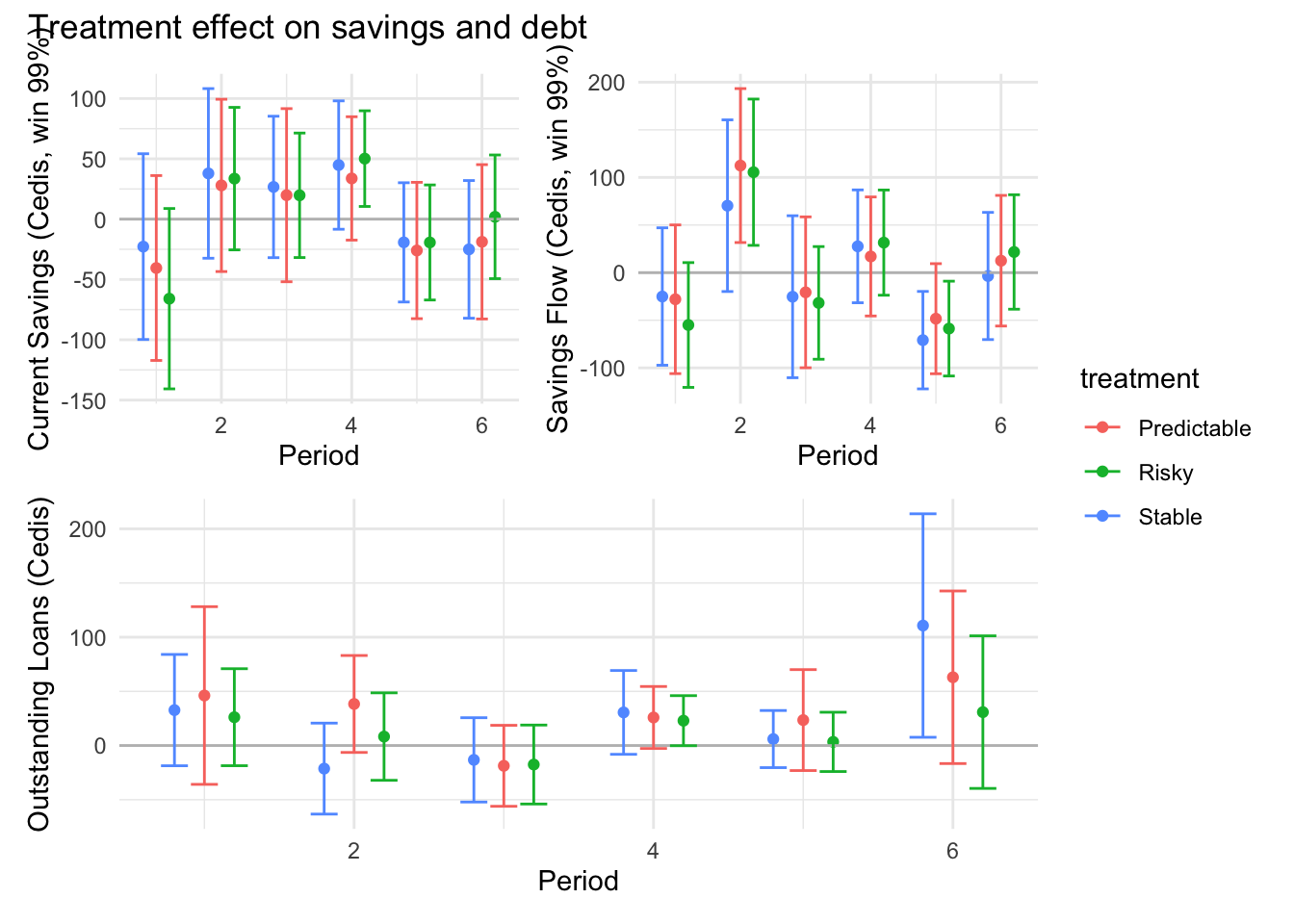
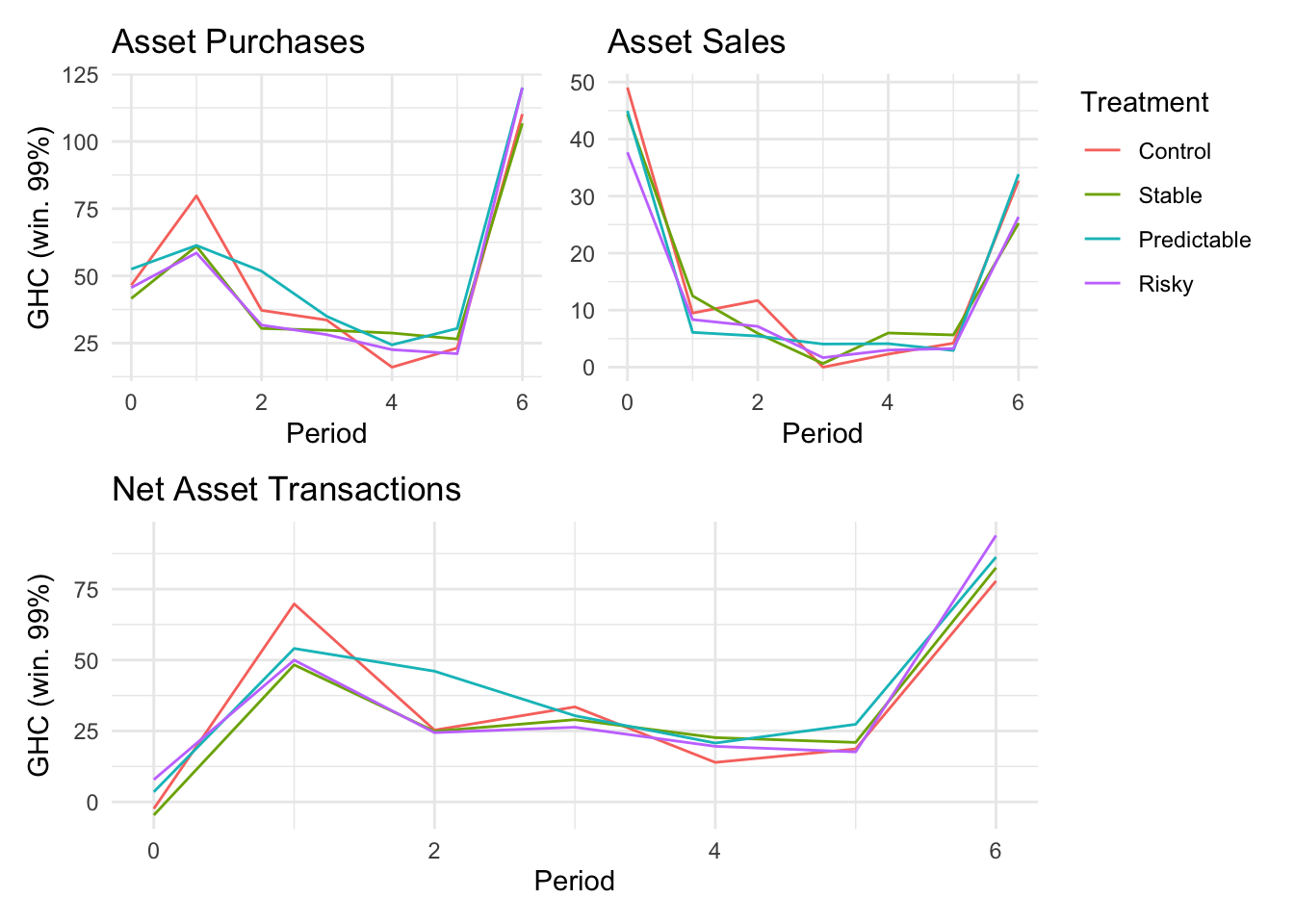
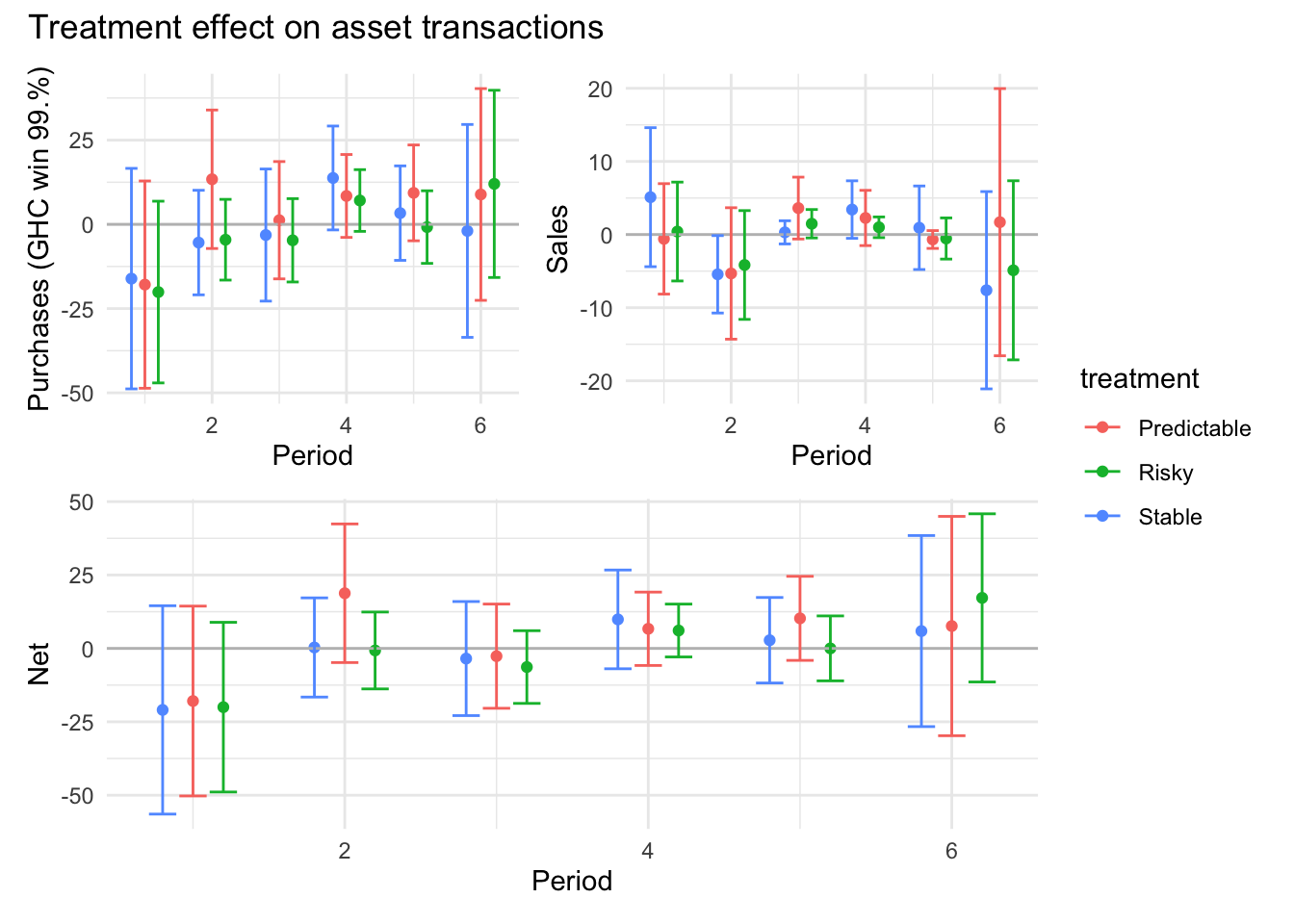
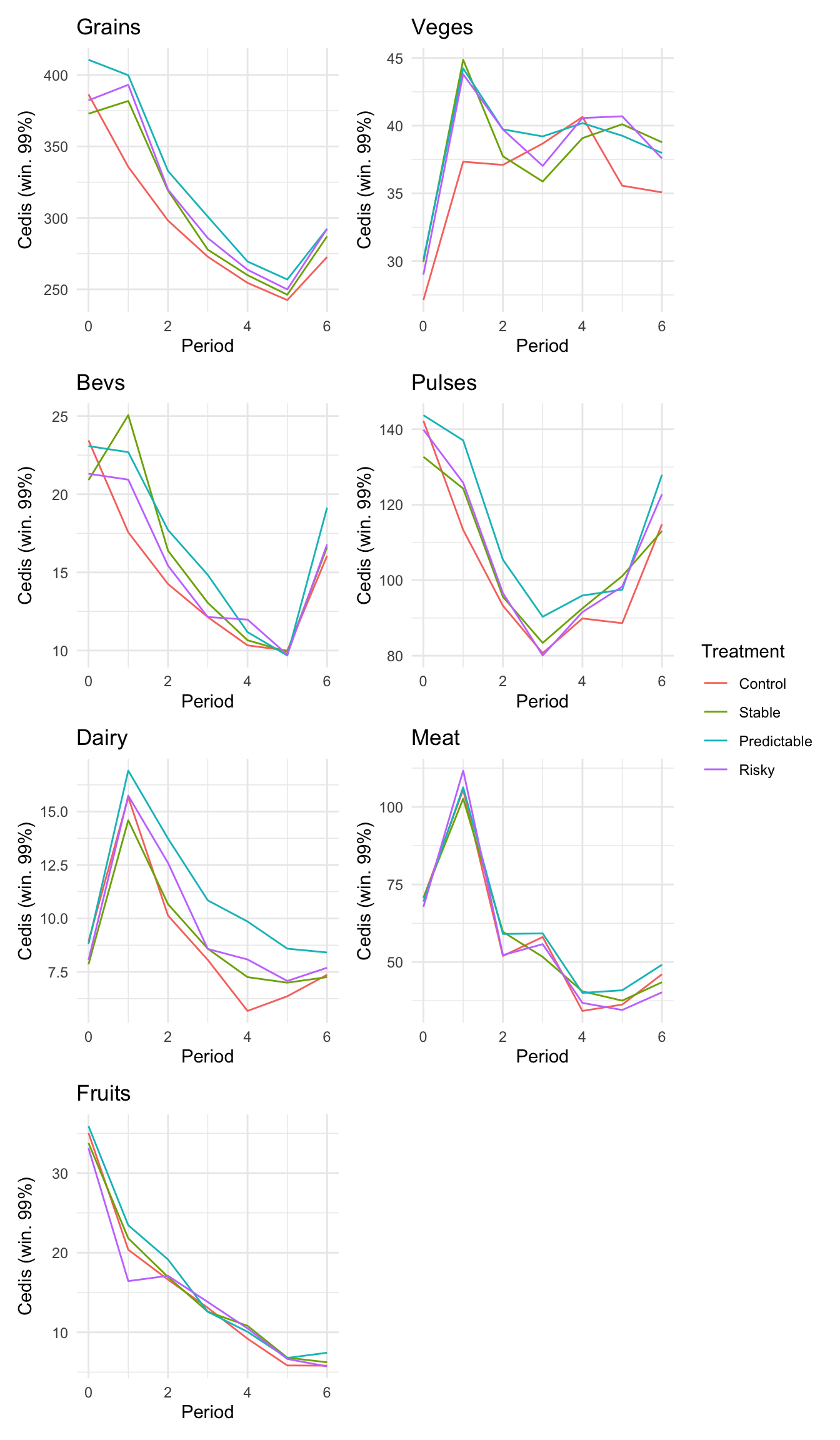
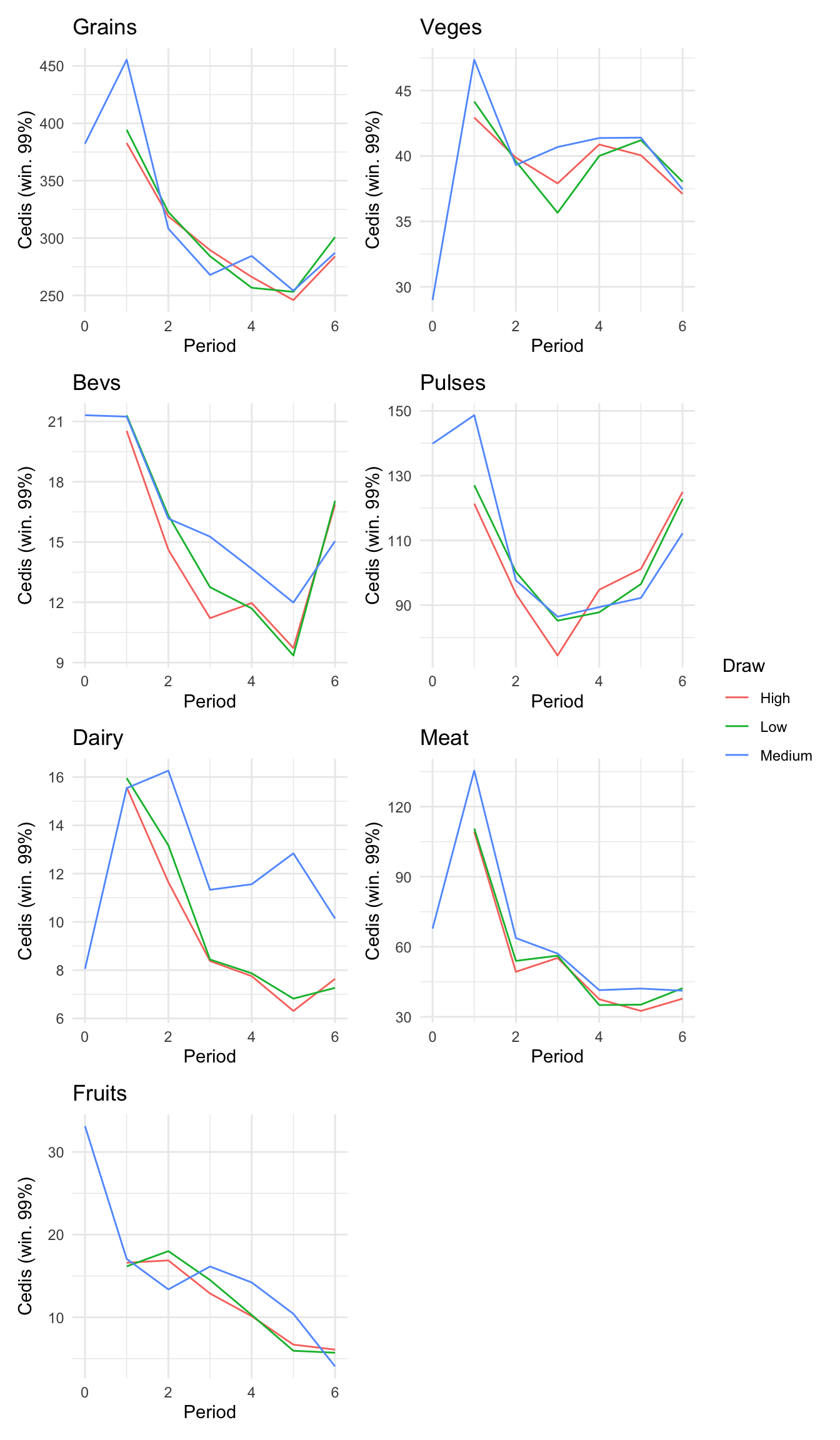
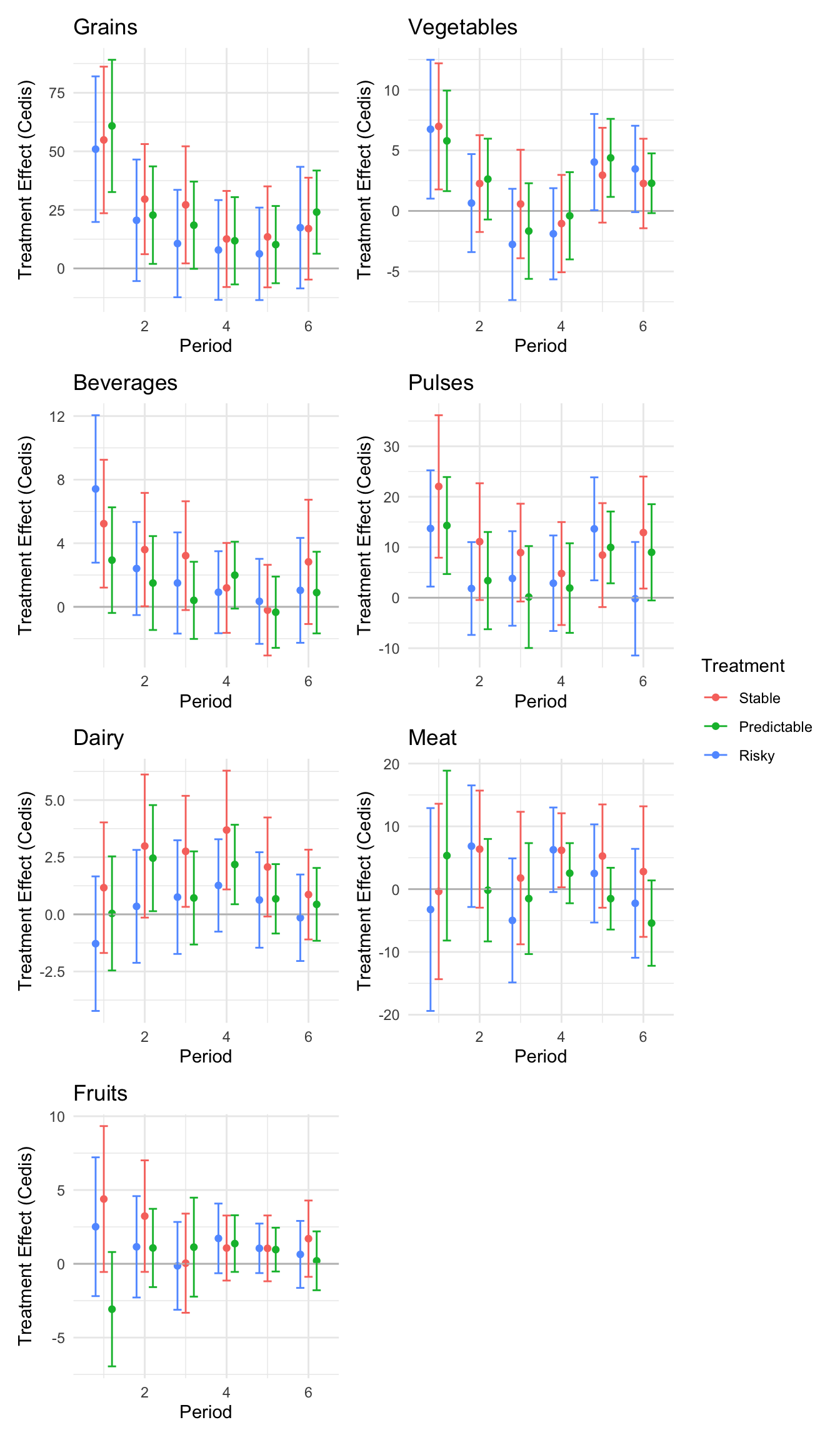
```{r}#| message: false#| warning: false#| label: regression-plot-functions# Function to run regressions for a variablegenerate_coeff_df <- function(estimate_data, var) { # Get the label for the variable varLabel <- variableLabels[var] # Define common controls specification controls <- paste0(var, "_bl + hh_size") period <- c(0, 1, 2, 3, 4, 5, 6) estimate_df <- map(period, ~ tidy( feols(as.formula(paste0(var, " ~ ", controls, " + i(treatment) | community_id")), cluster = "community_id", data = estimate_data %>% filter(period == .x) ), conf.int = TRUE )) # Aggreagte estimate_df into one, adding a period column estimate_df <- bind_rows(estimate_df, .id = "period") %>% filter(str_detect(term, "treatment")) %>% filter(period != 1) %>% mutate( period = as.numeric(period) - 1, treatment = case_when( term == "treatment::1" ~ "Stable", term == "treatment::2" ~ "Predictable", term == "treatment::3" ~ "Risky", ), # add jitter to period for plotting based on treatment period = case_when( treatment == "Stable" ~ period - 0.2, treatment == "Predictable" ~ period, treatment == "Risky" ~ period + 0.2, ) ) %>% select(!c(term)) estimate_df}effects_grapher <- function(data, ylabel) { ggplot(data, aes(x = period, y = estimate, group = treatment, color = treatment)) + geom_point() + geom_hline(yintercept = 0, color = "grey") + geom_errorbar(aes(ymin = conf.low, ymax = conf.high)) + ylab(ylabel) + xlab("Period")}```
Note
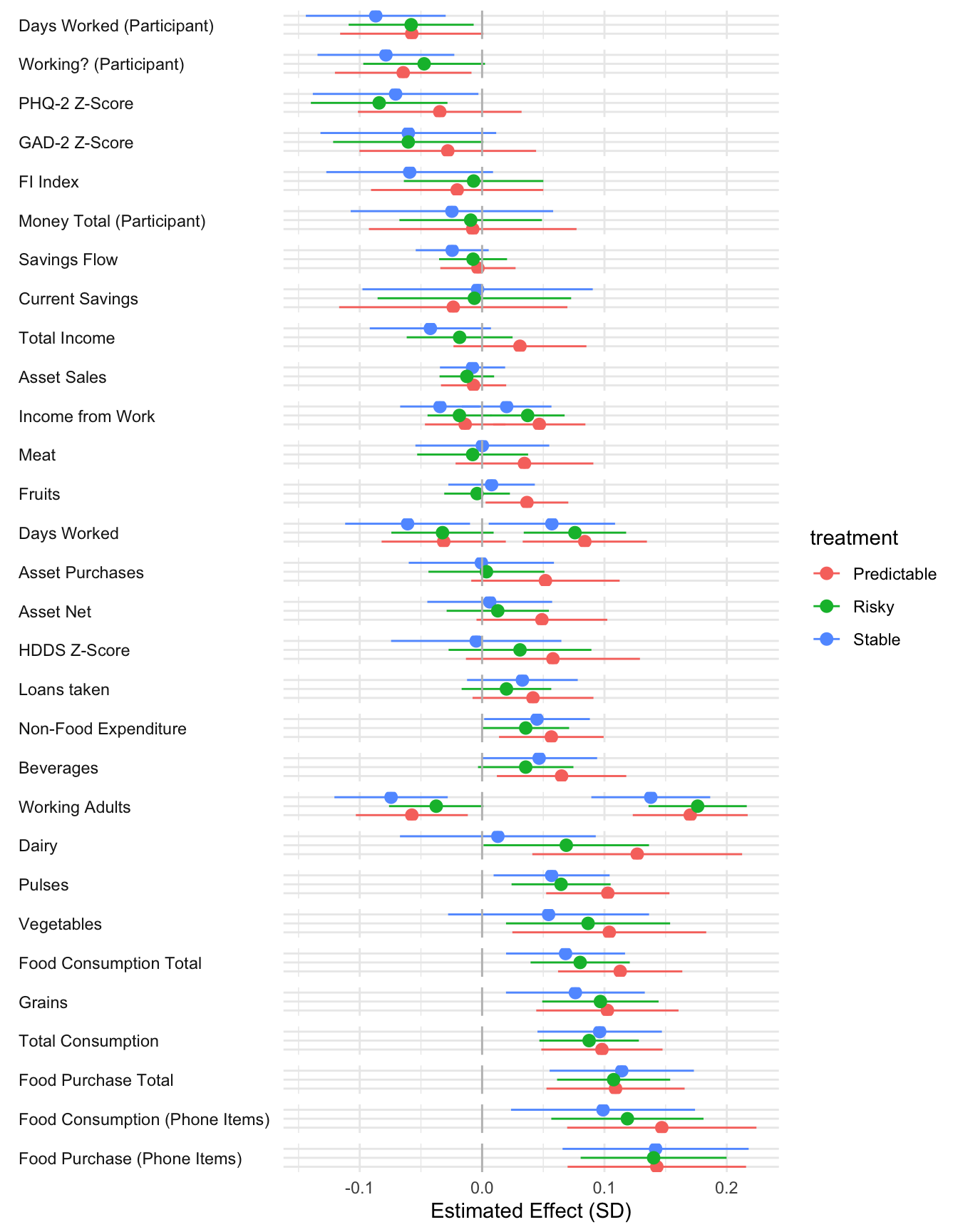
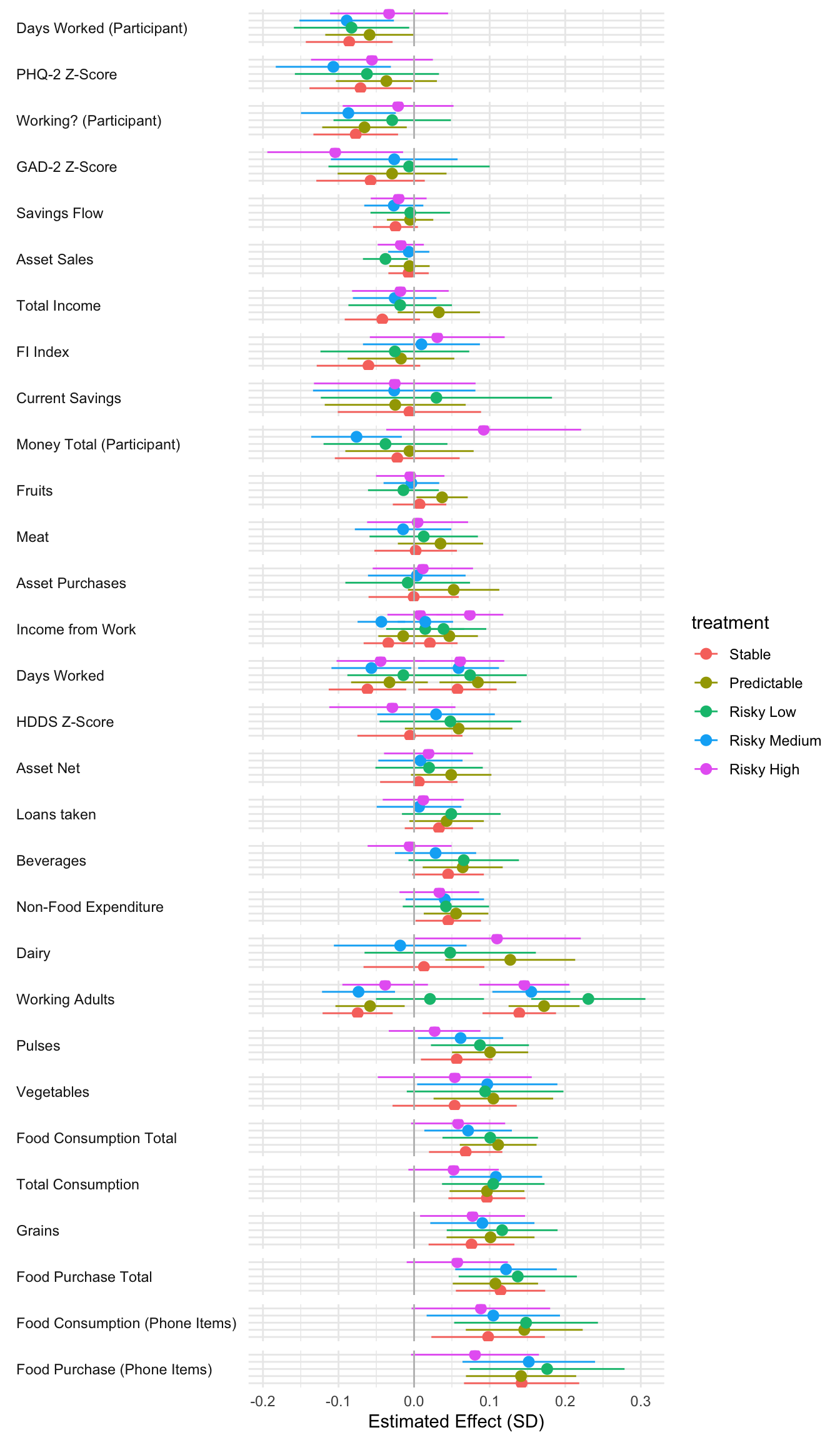
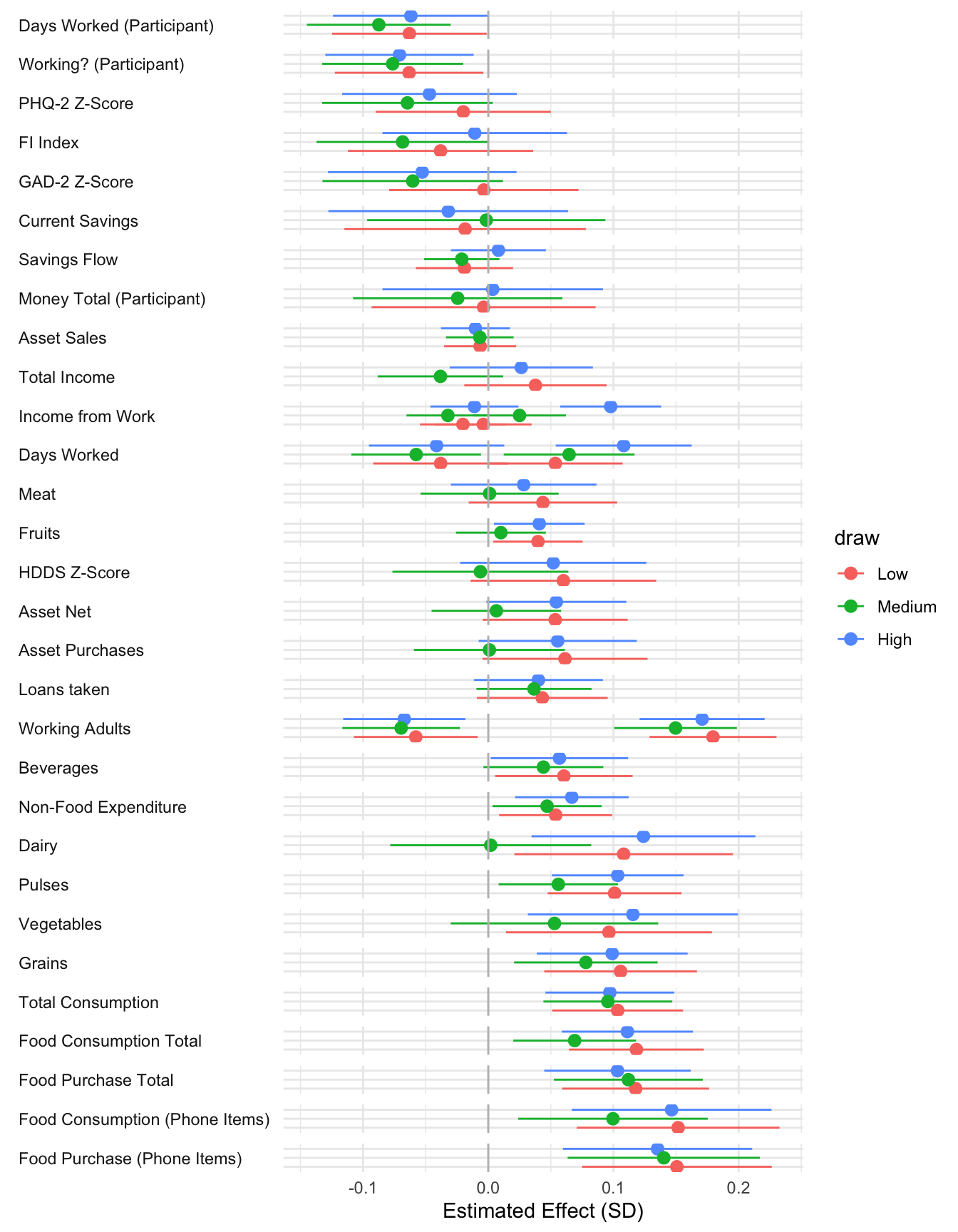
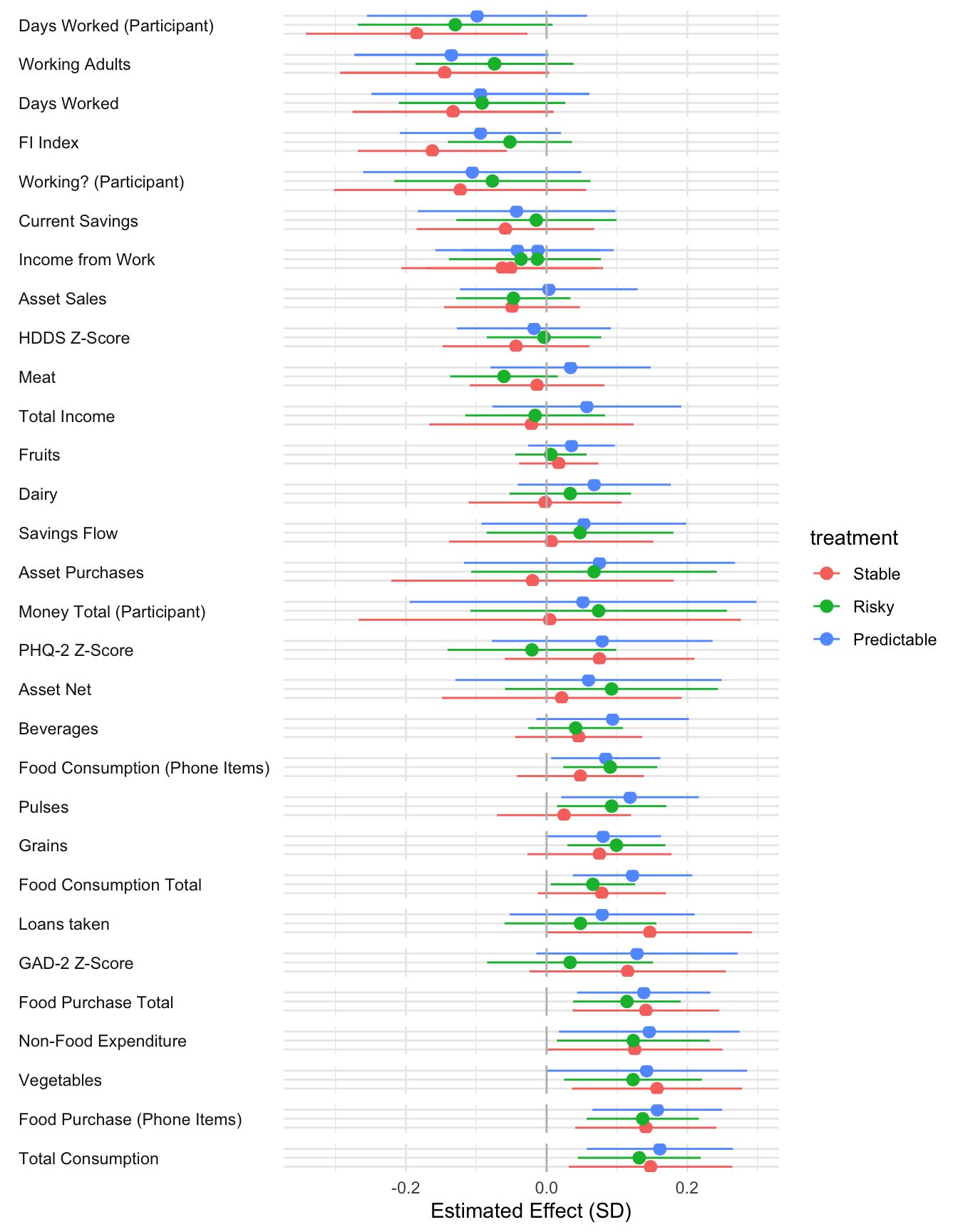
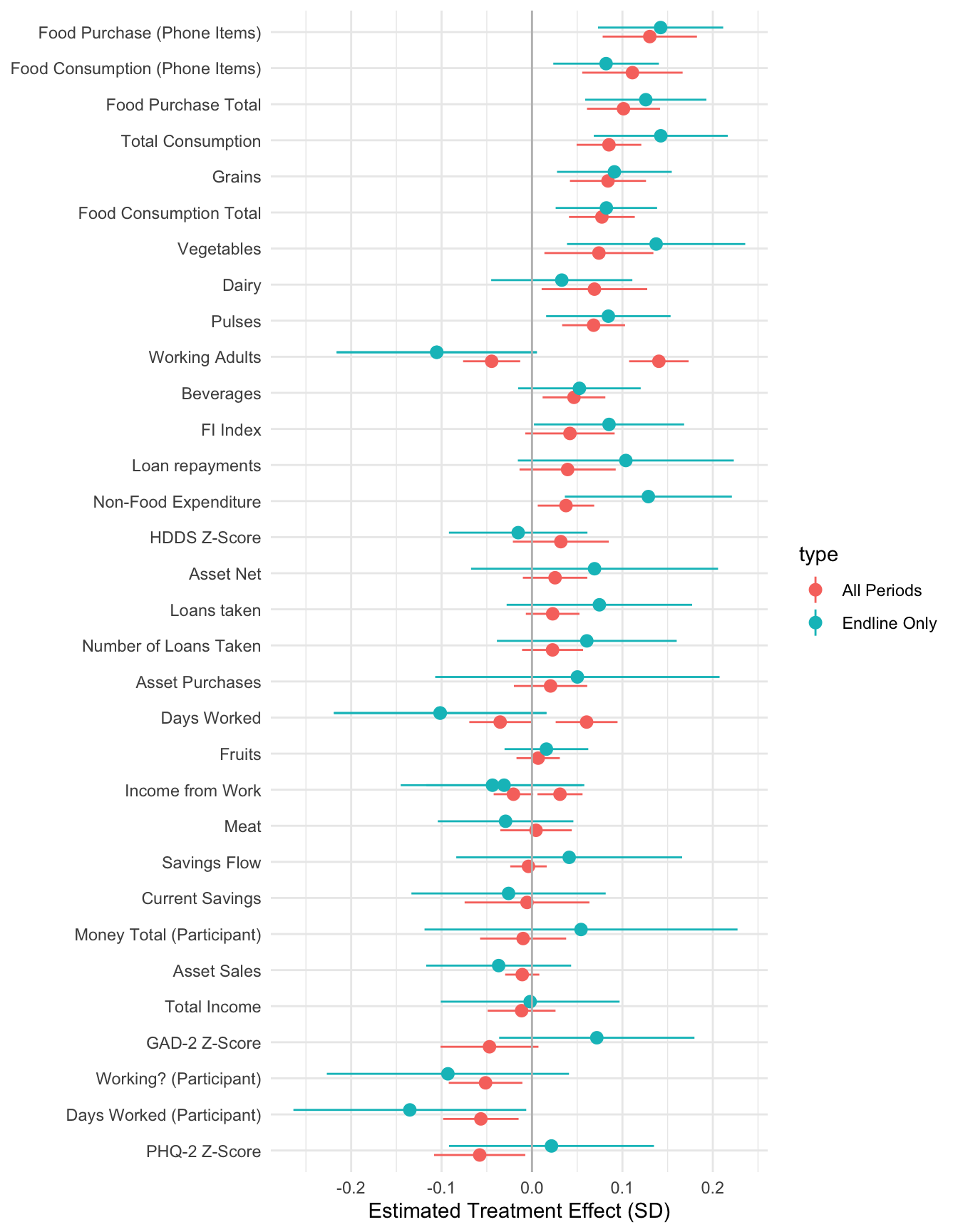
All regressions control for household size and wealth at census. They also include district_id, period, wave, enum_id, day_of_week and cohort fixed effects
The N for mental health outcomes is lower than for other outcomes. The cause for the lower observation count is due to 62 endline surveys that were conducted with a household member other than the participant. In these cases we did not ask for responses to the mental health questions.
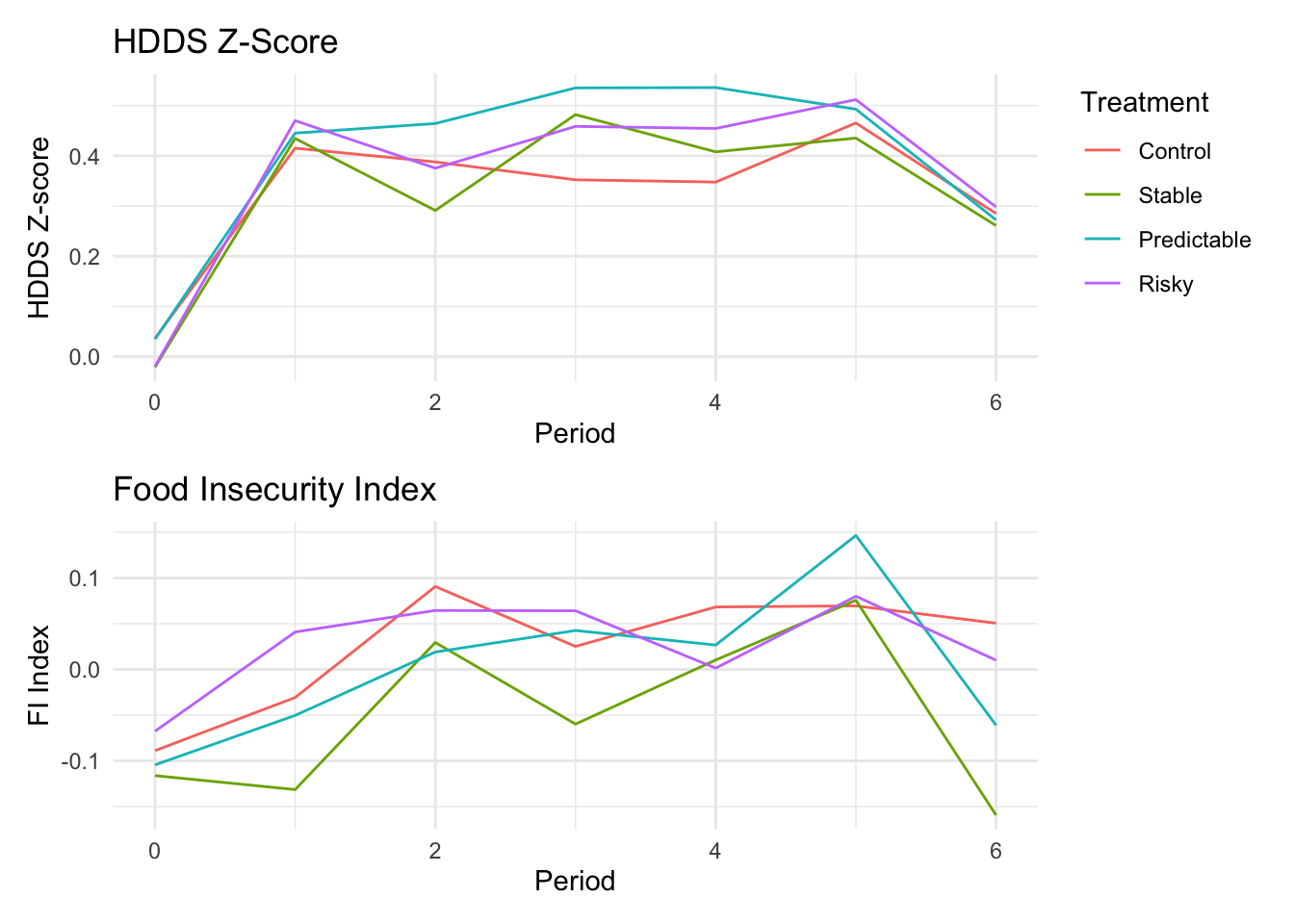
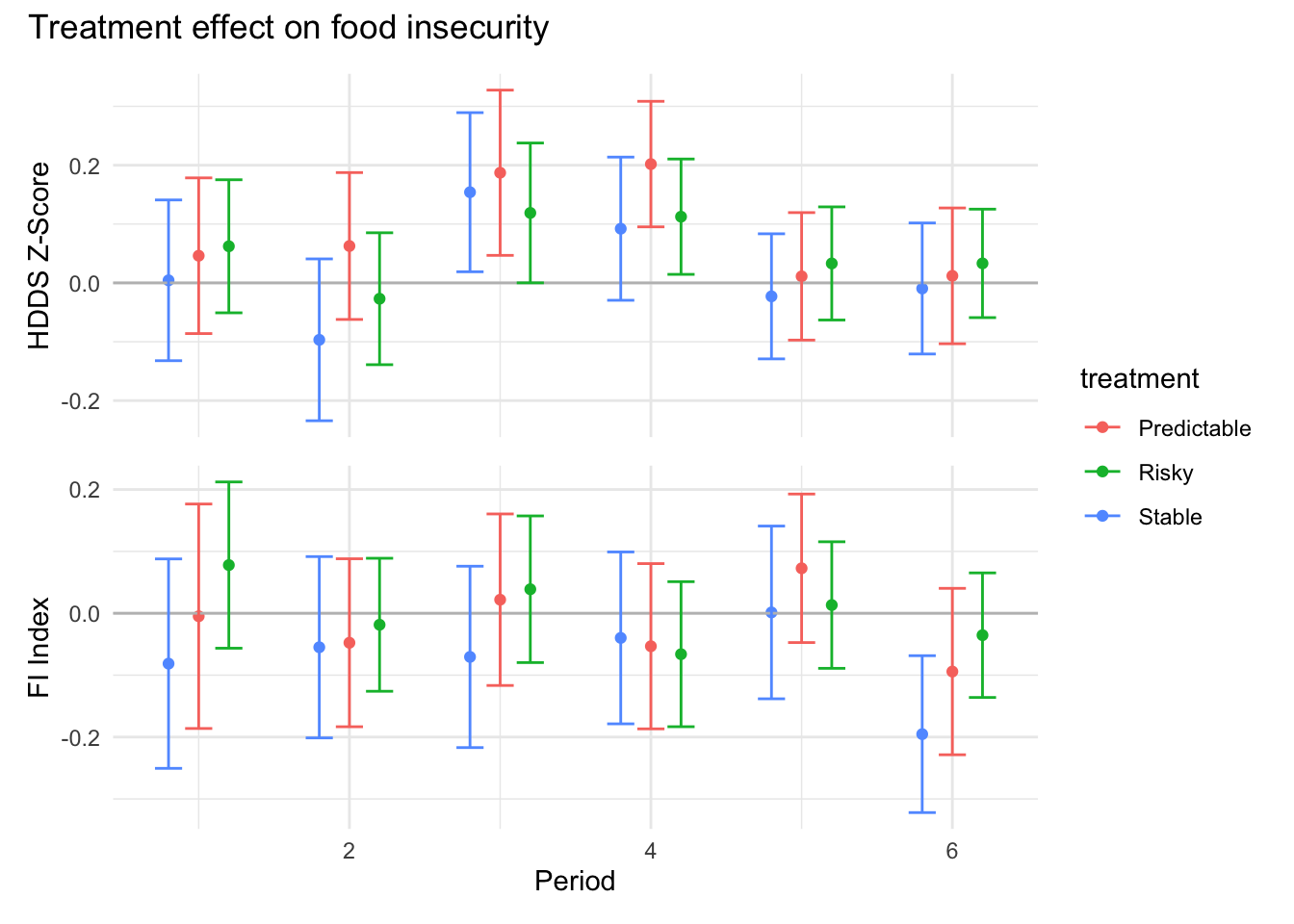
HDDS Z is a z-score of the FAO Household Dietary Diversity Score (HDDS). Higher score is better. The measure is a simple sum of the number of different food groups consumed in a given period.
Food Insecurity index is an Anderson index constructed from food insecurity questions. These questions are likert-scale questions about food insecurity experiences in the past period. A higher score indicates greater food insecurity.
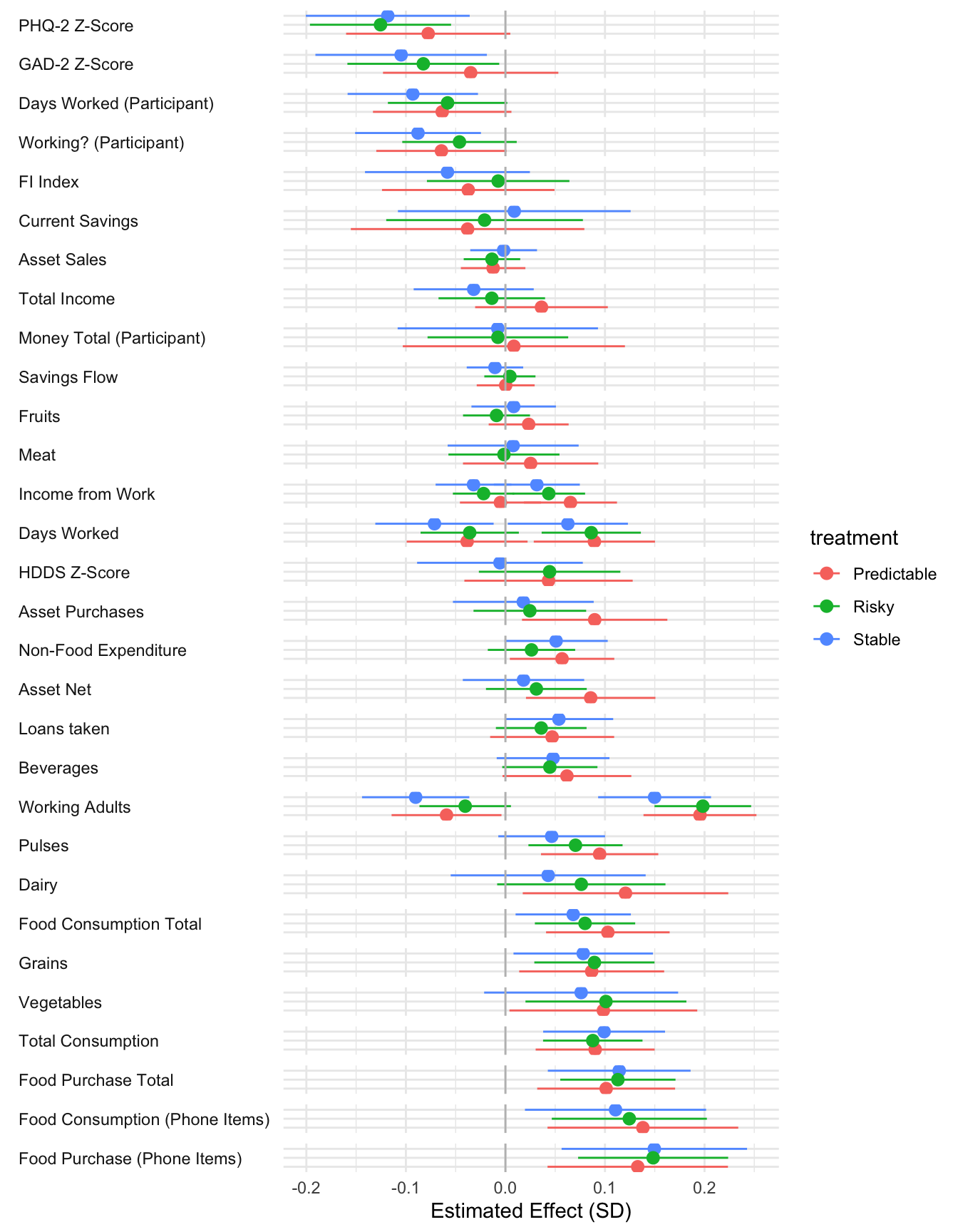
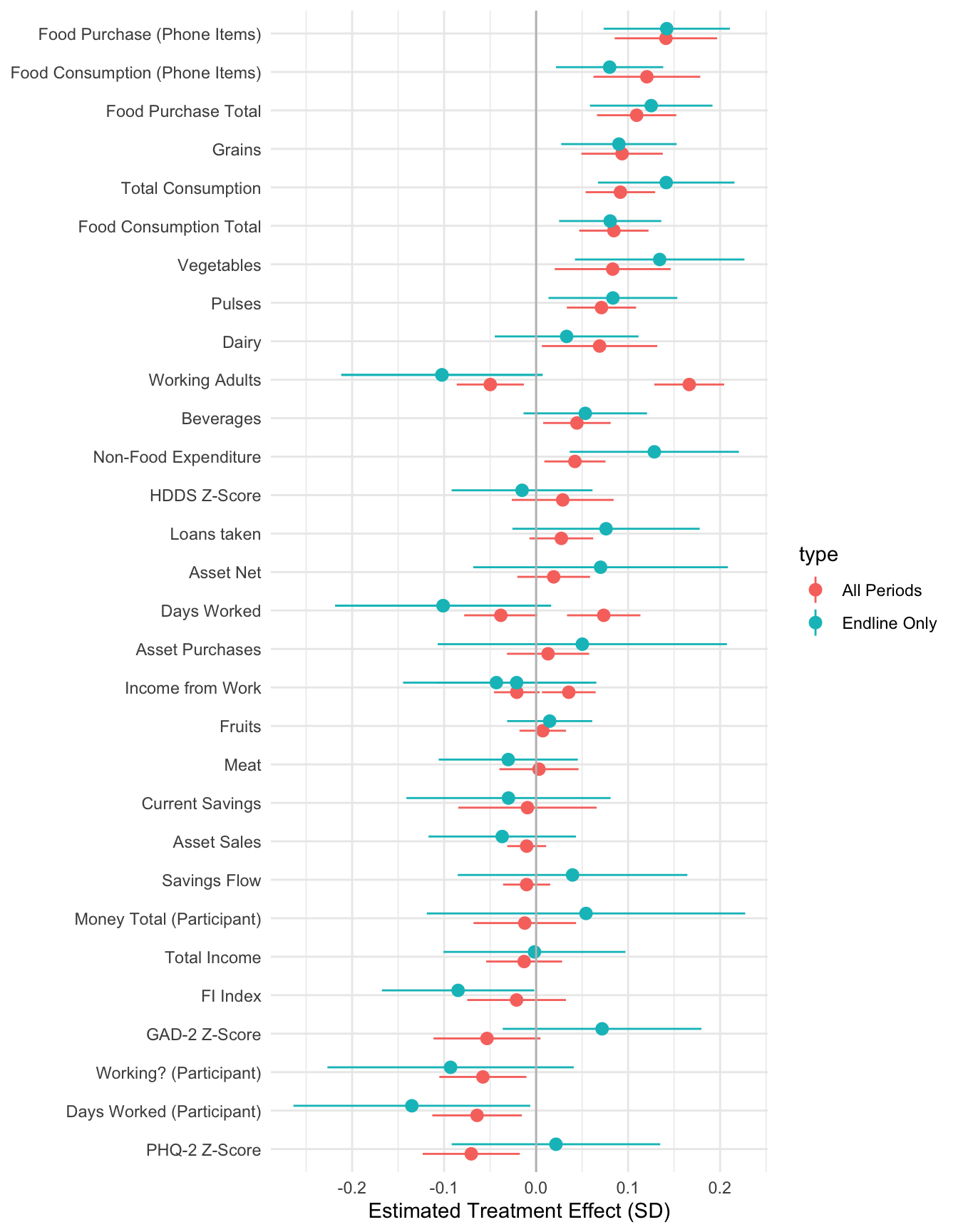
The following results only include data from the endline and thus do not have period fixed effects. They are othwerwise identical to the main treatment results.
```{r}#| warning: false#| message: false#| label: models-crowding-out#| tbl-cap: "Testing for crowding out"run_regressions_short <- function(var, reg_data) { fe_spec <- "| district_id + period + wave + enum_id + day_of_week + cohort" controls <- paste0(var, "_bl + hh_size + census_wealth_index") formula <- as.formula(paste0(var, " ~ ", controls, " + i(treatment) ", fe_spec)) model <- feols( formula, cluster = "hh_id", data = reg_data, collin.tol = 1e-5 ) return(model)}# Run the regression for working adults, days worked, total income and work income with main spec on period 1-3 data using "non_corrected" income variablesinitial <- map(c("working_adults", "days_worked", "money_work_99"), ~ run_regressions_short( var = ., reg_data = df %>% filter(period <= 3))) %>% set_names(c("Working Adults (Original P1-3)", "Days Worked (Original P1-3)", "Work Income (Original P1-3)"))# Run the regression for working adults, days worked, total income and work income with main spec on period 1-3 data using "corrected" income variablescorrected <-map(c("working_adults_corrected", "days_worked_corrected", "money_work_corrected_99"), ~ run_regressions_short( var = ., reg_data = df %>% filter(period <= 3))) %>% set_names(c("Working Adults (Corrected P1-3)", "Days Worked (Corrected P1-3)", "Work Income (Corrected P1-3)"))second_half_no_endline <- map(c("working_adults", "days_worked", "money_work_99"), ~ run_regressions_short( var = ., reg_data = df %>% filter(period > 3 & period < 6))) %>% set_names(c("Working Adults (Original P4-5)", "Days Worked (Original P4-5)", "Work Income (Original P4-5)"))# Run the regression for working adults, days worked, total income and work income with main spec on period 4-6 data using "non-corrected" income variablessecond_half <- map(c("working_adults", "days_worked", "money_work_99"), ~ run_regressions_short( var = ., reg_data = df %>% filter(period > 3))) %>% set_names(c("Working Adults (Original P4-6)", "Days Worked (Original P4-6)", "Work Income (Original P4-6)"))makeTable(c( initial[1], corrected[1], second_half[1], second_half_no_endline[1], initial[2], corrected[2], second_half[2], second_half_no_endline[2], initial[3], corrected[3], second_half[3], second_half_no_endline[3]))```