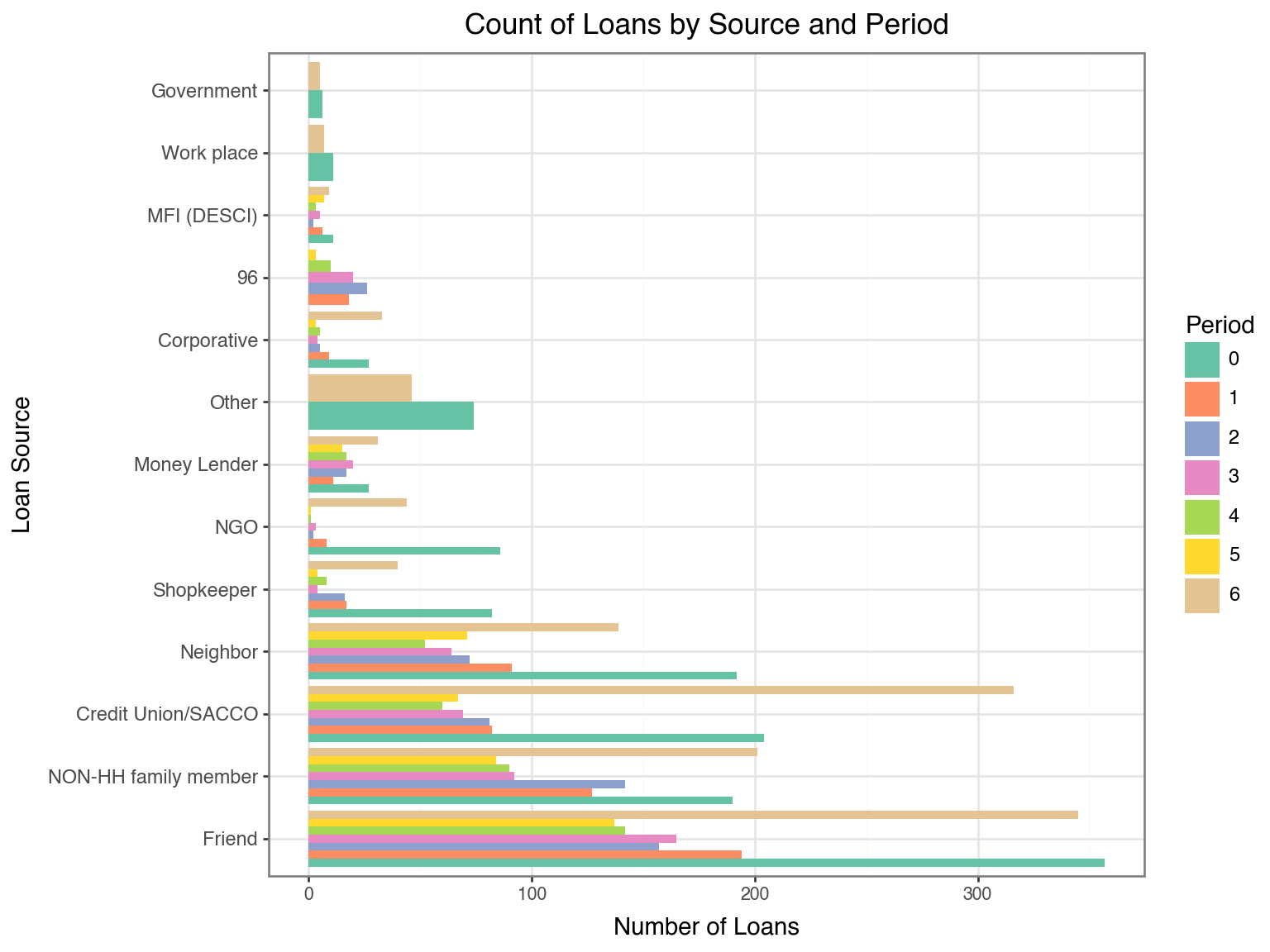
Discussed on March 3, 2026. Meeting notes available here.
Big Takeaways:
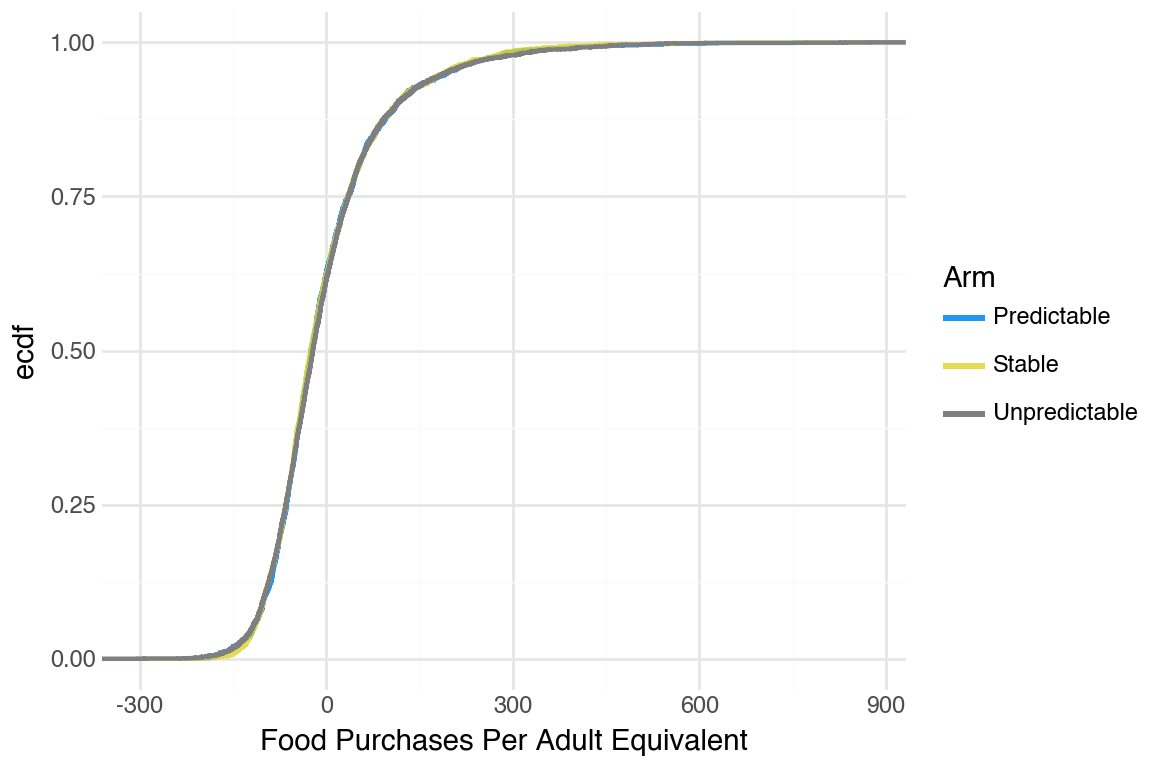
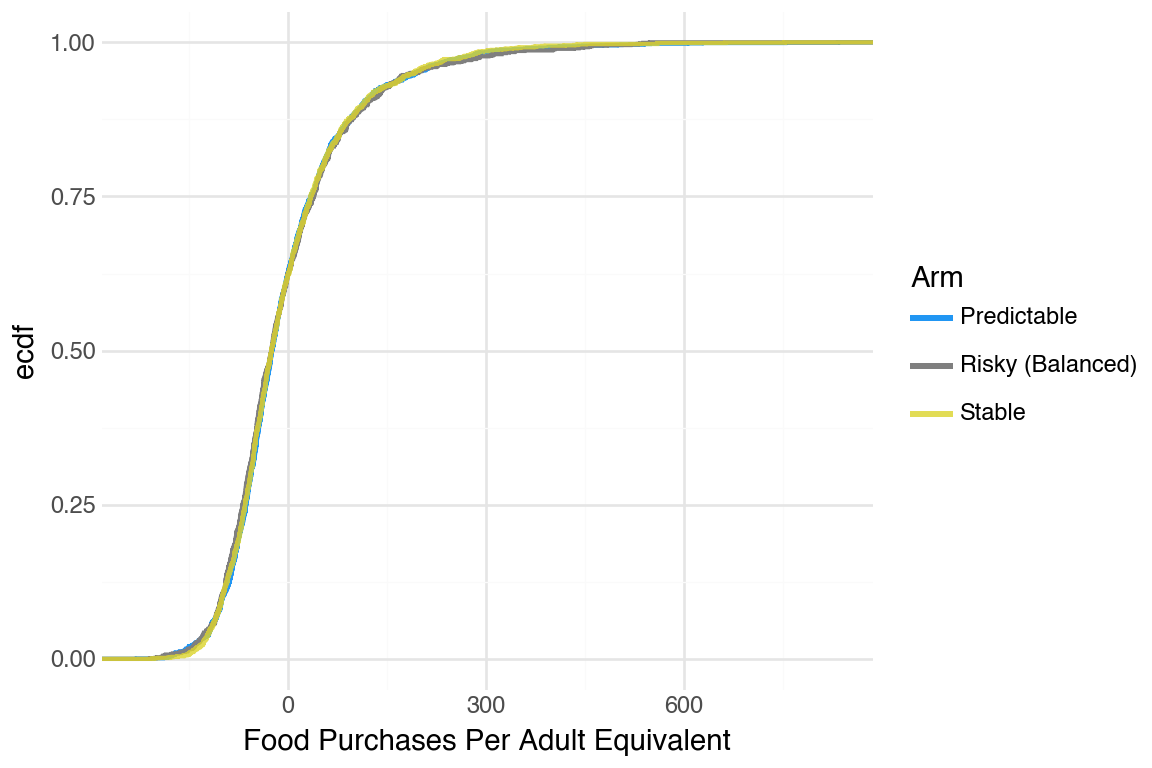
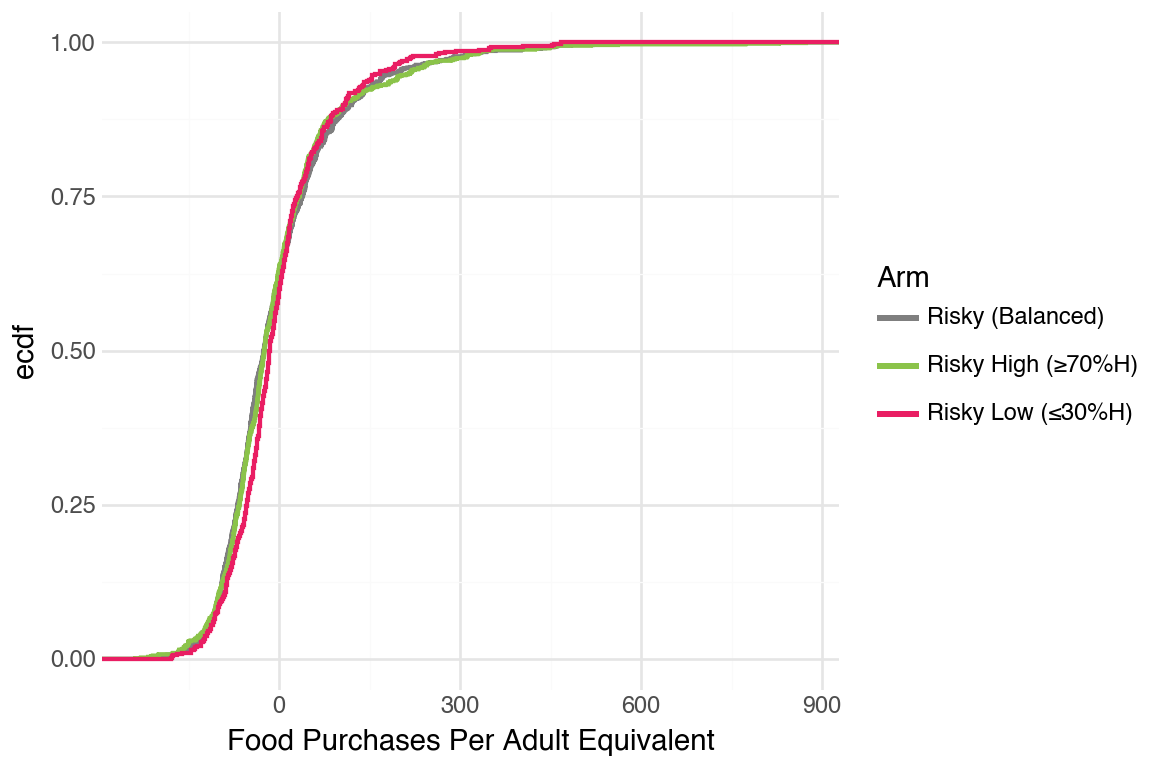
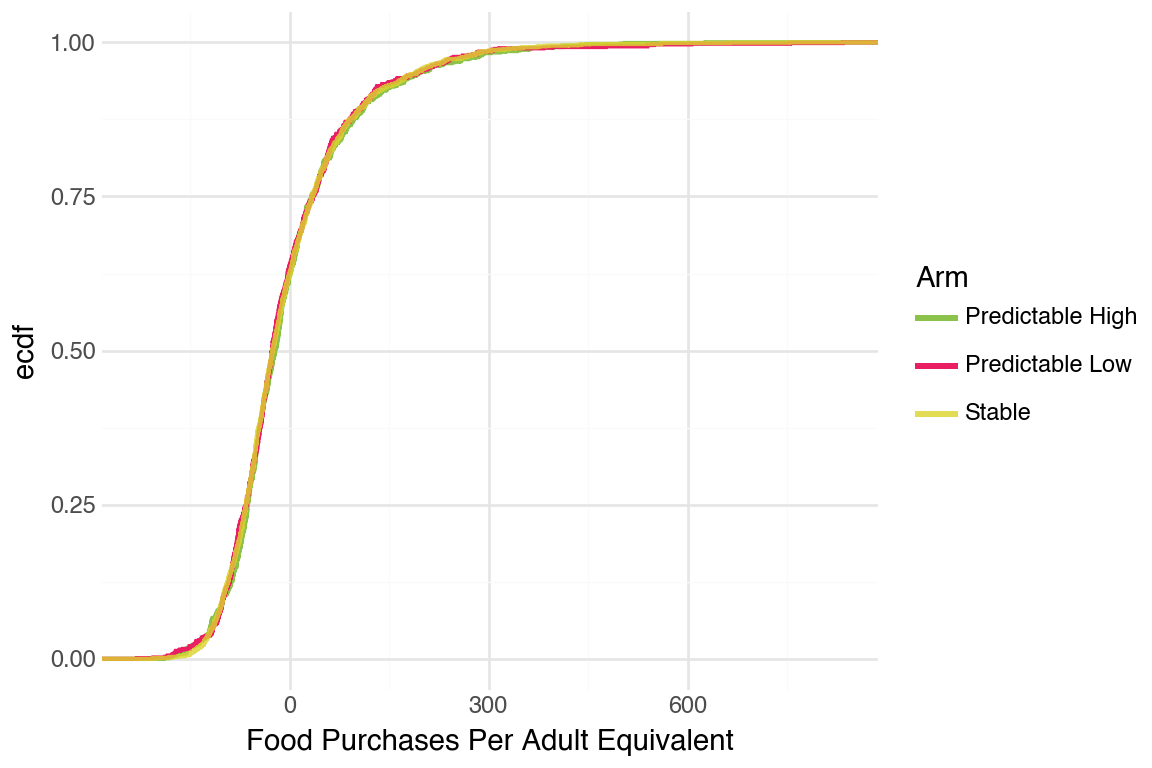
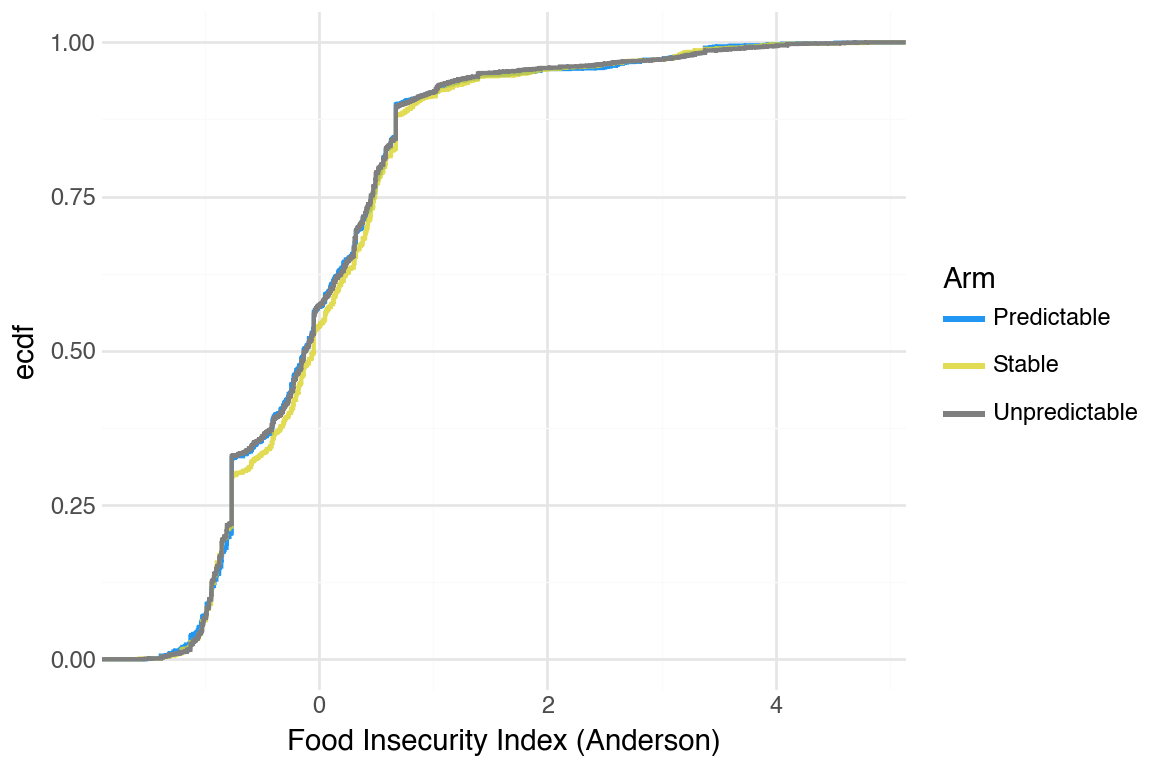
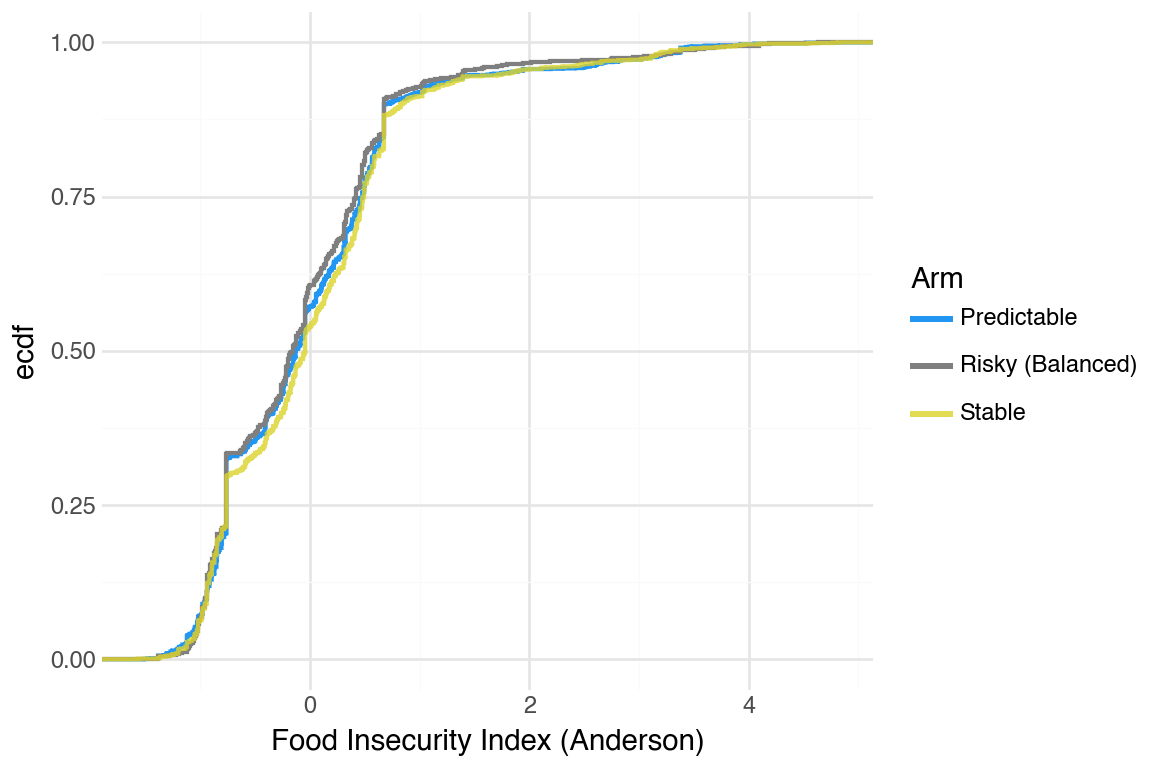
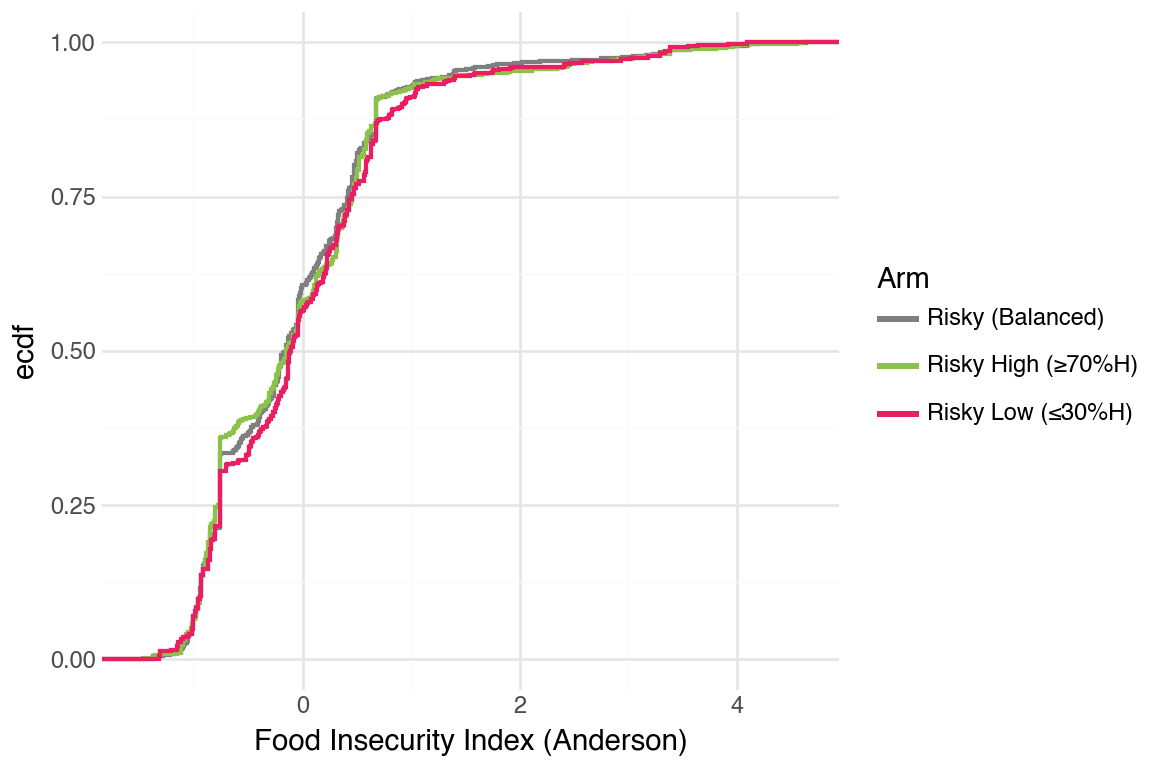
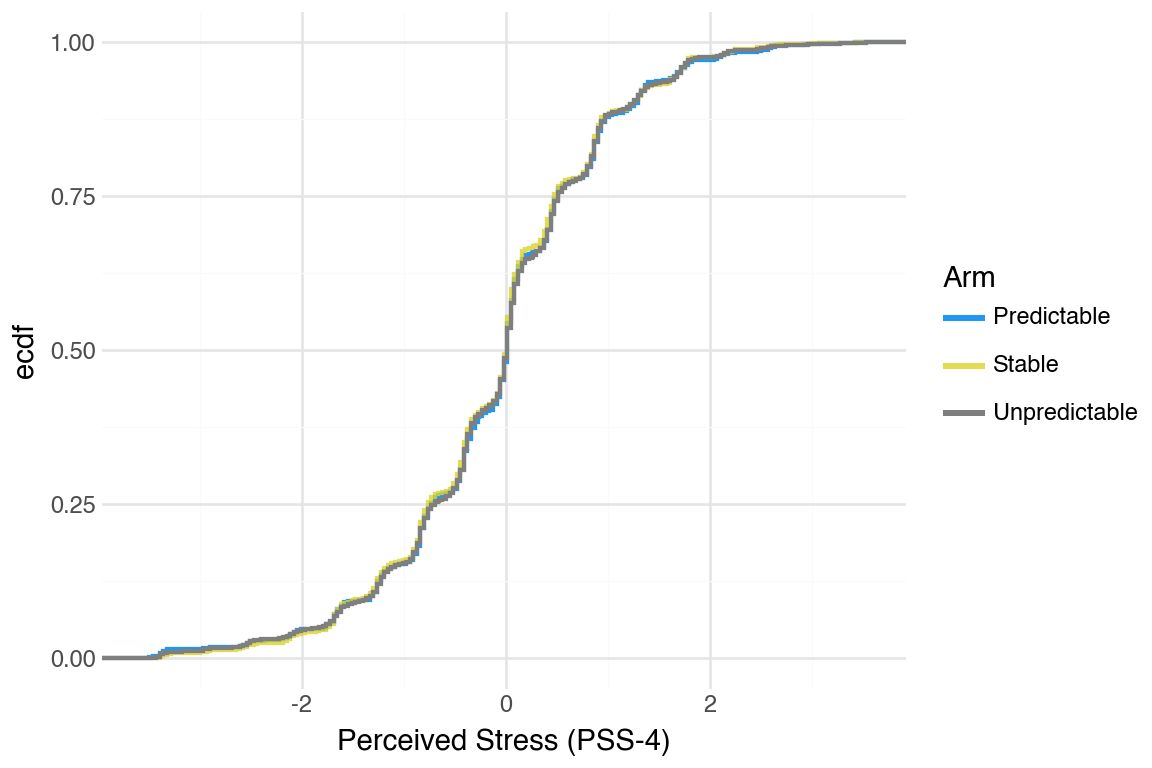
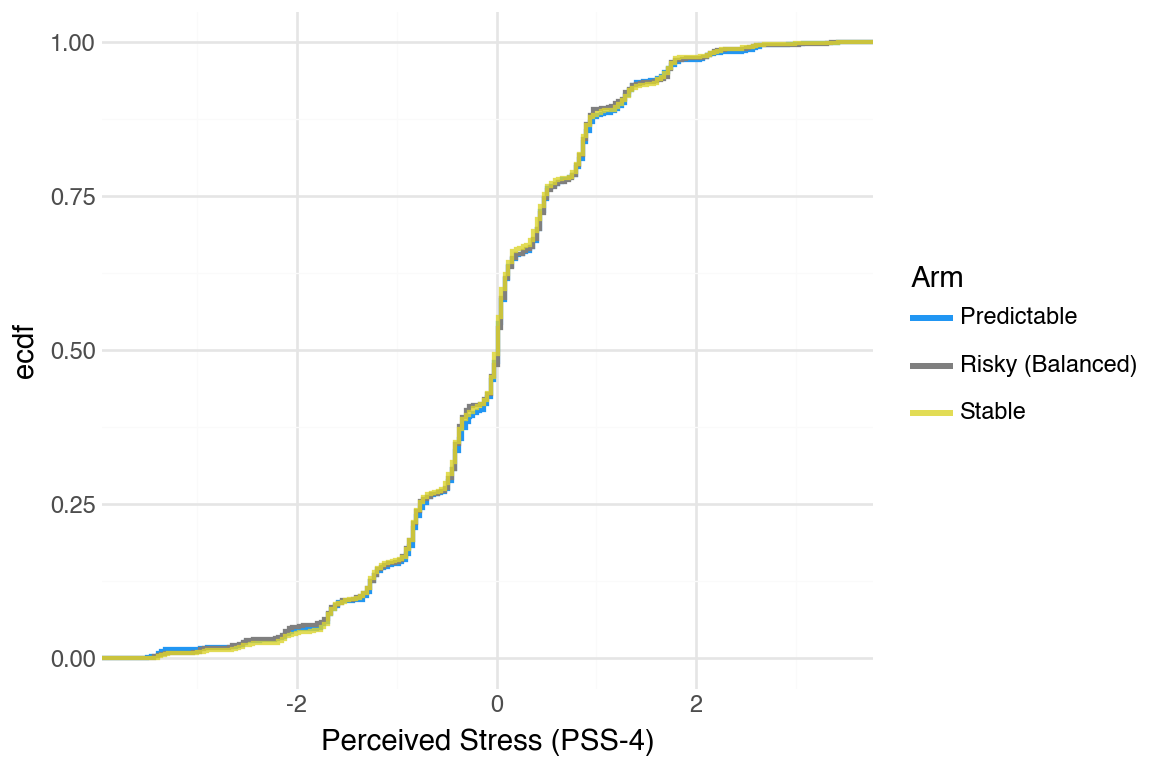
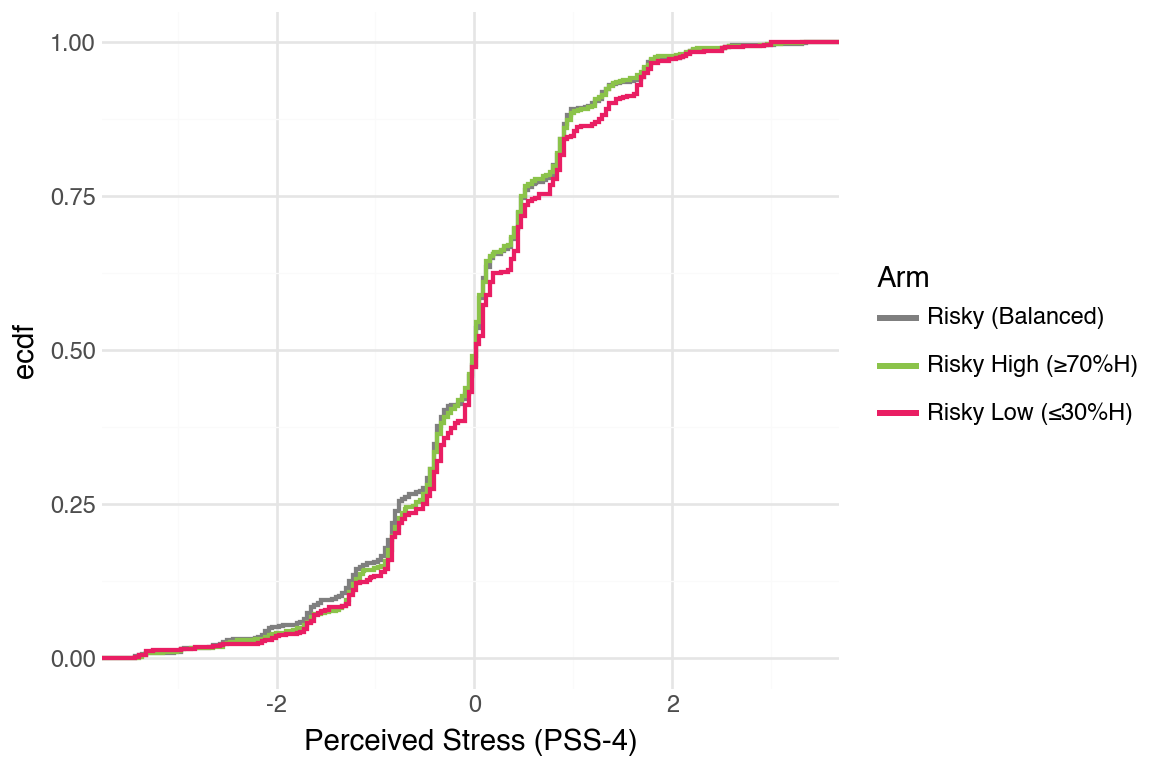
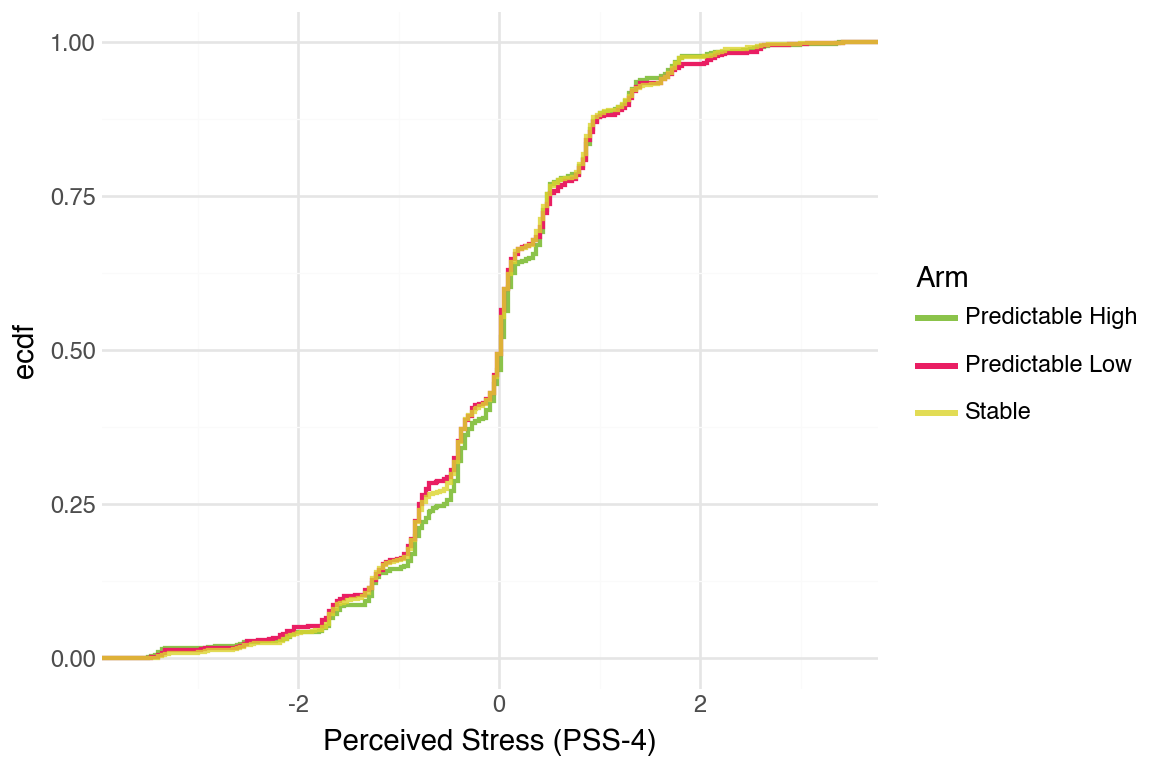
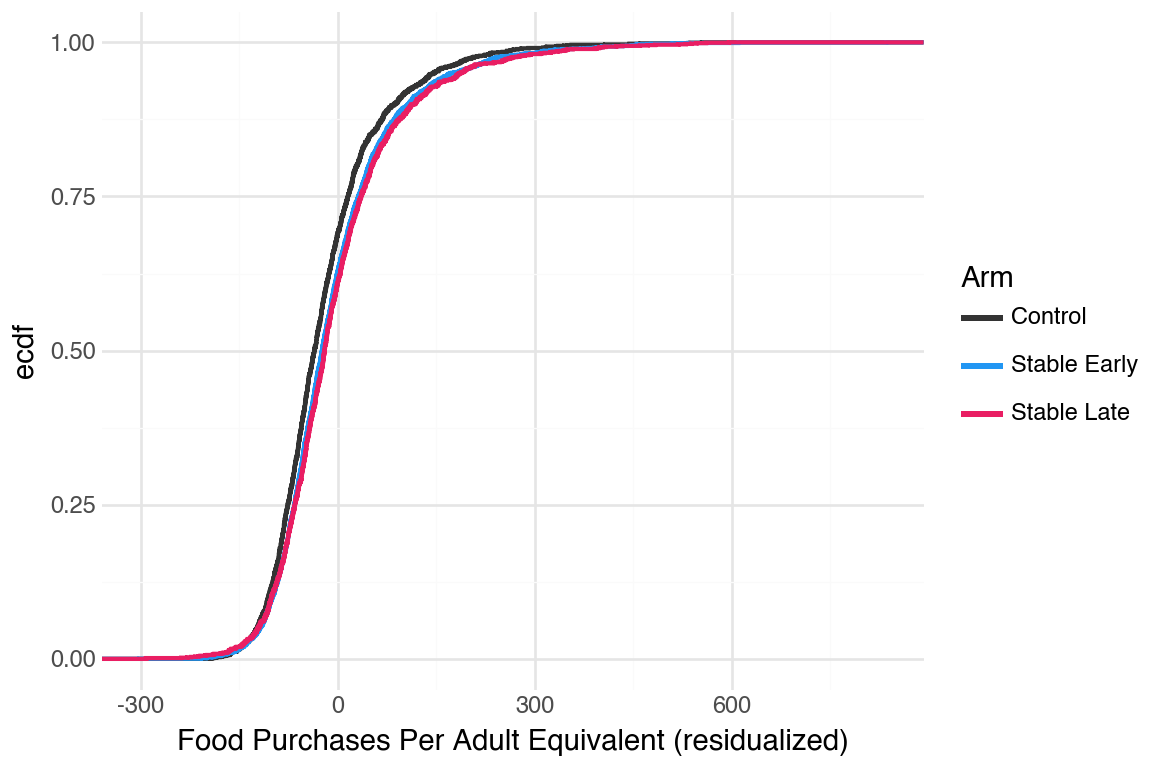
CDFs were hard to tell apart. One pattern that was noticeable was that Stable arm did better than the others.
People smoothed food purchases very well. We decided to take a look at the adult equivalent version to see if that revealed more differences between arms.
We also decided to take a look at debt to see if that was a reasonable source of consumption smoothing or sink of people spending their money
Analysis for this week:
Generate CDFs for the adult equivalent version of food purchases (no noticeable difference)
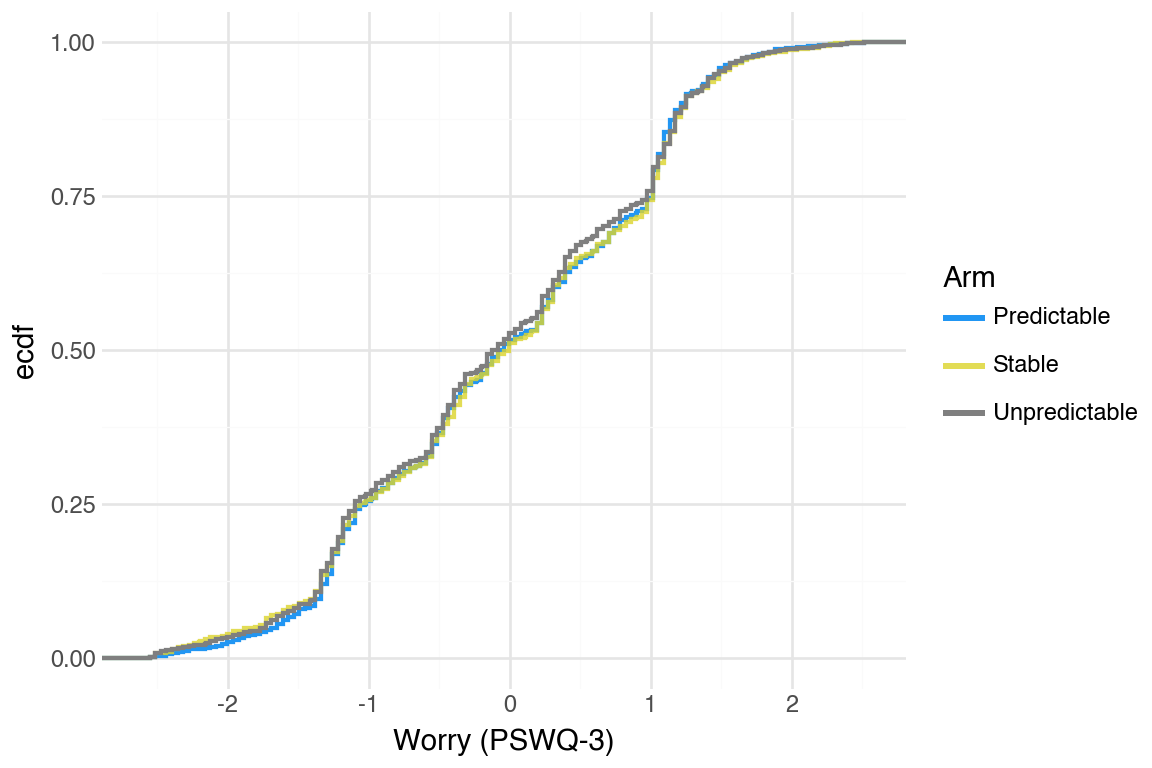
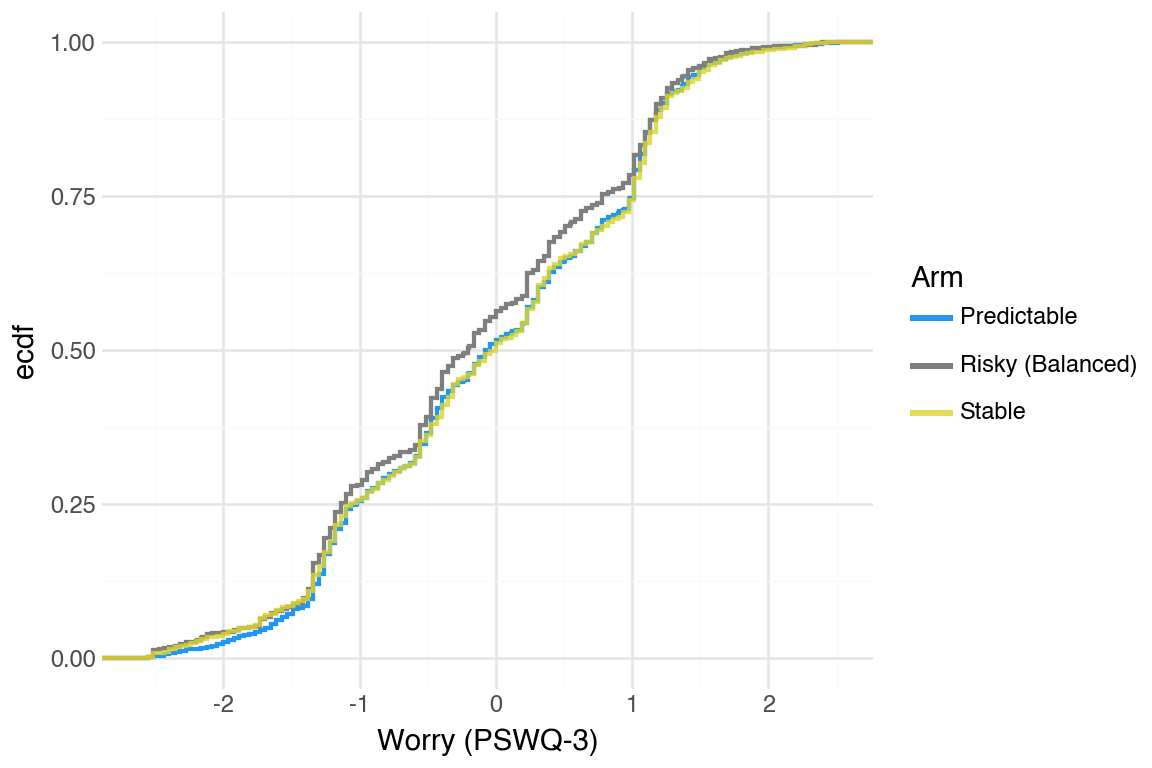
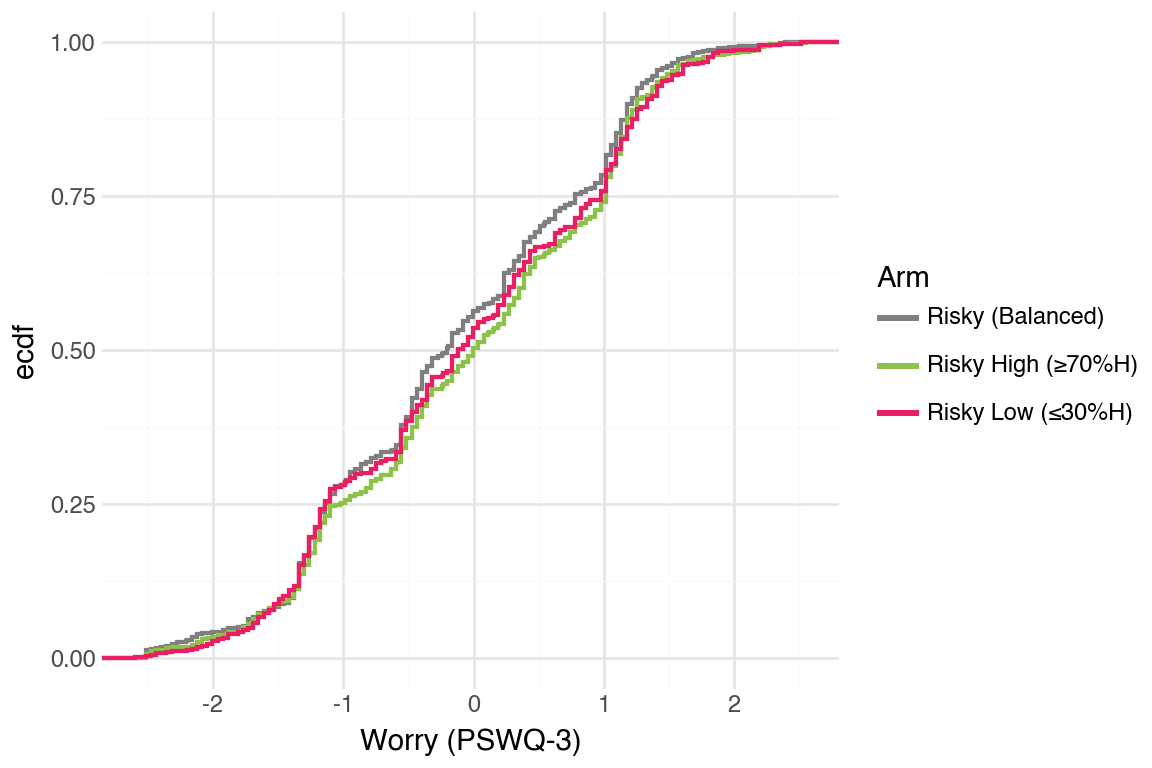
Generate CDFs for other mental health outcomes (PSS-4, PSWQ-3); separation is even smaller compared to the PHQ and GAD
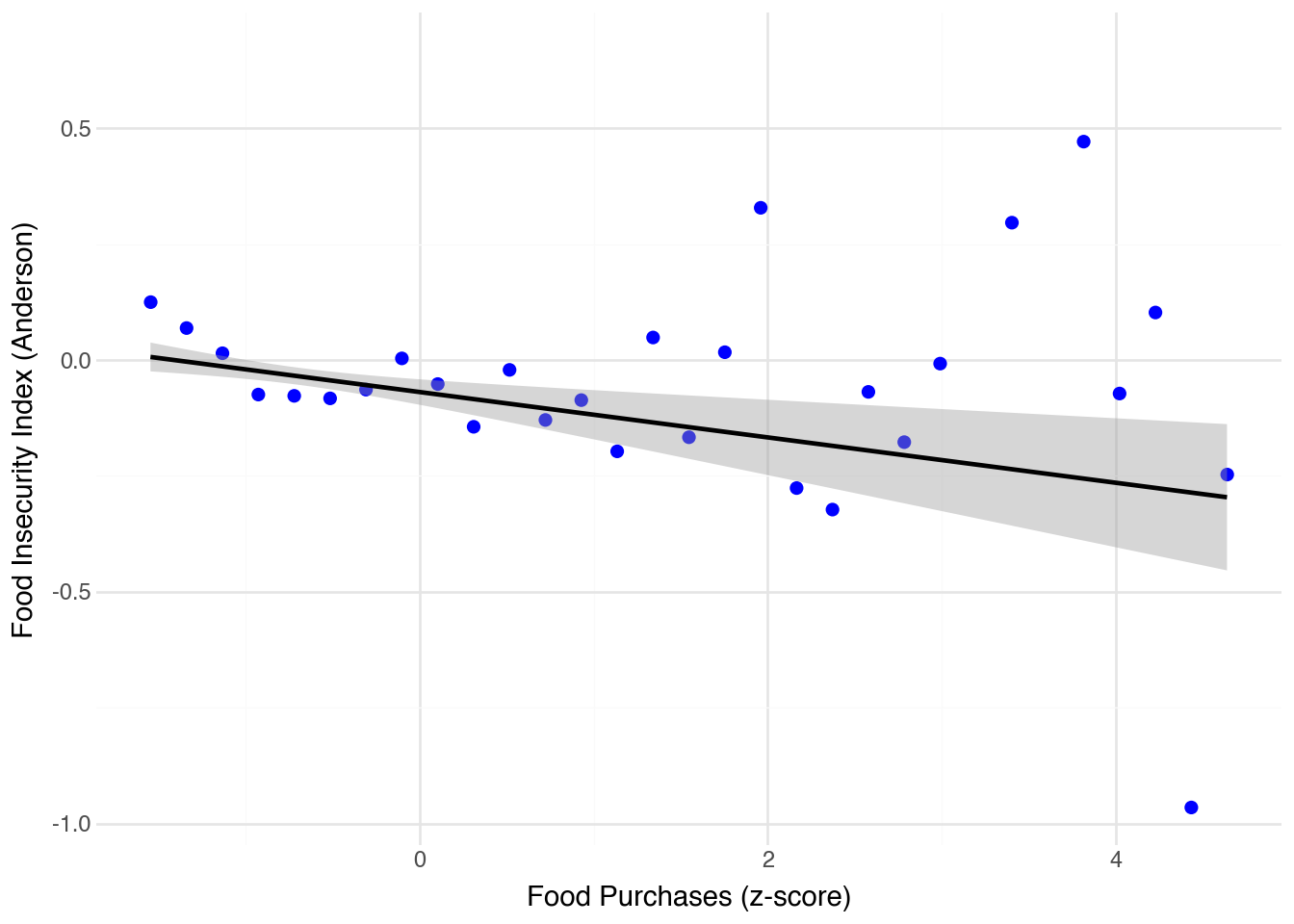
Correlation between food insecurity and food purchases: yes there is a correlation in the degree we expect. However, it is not too strong
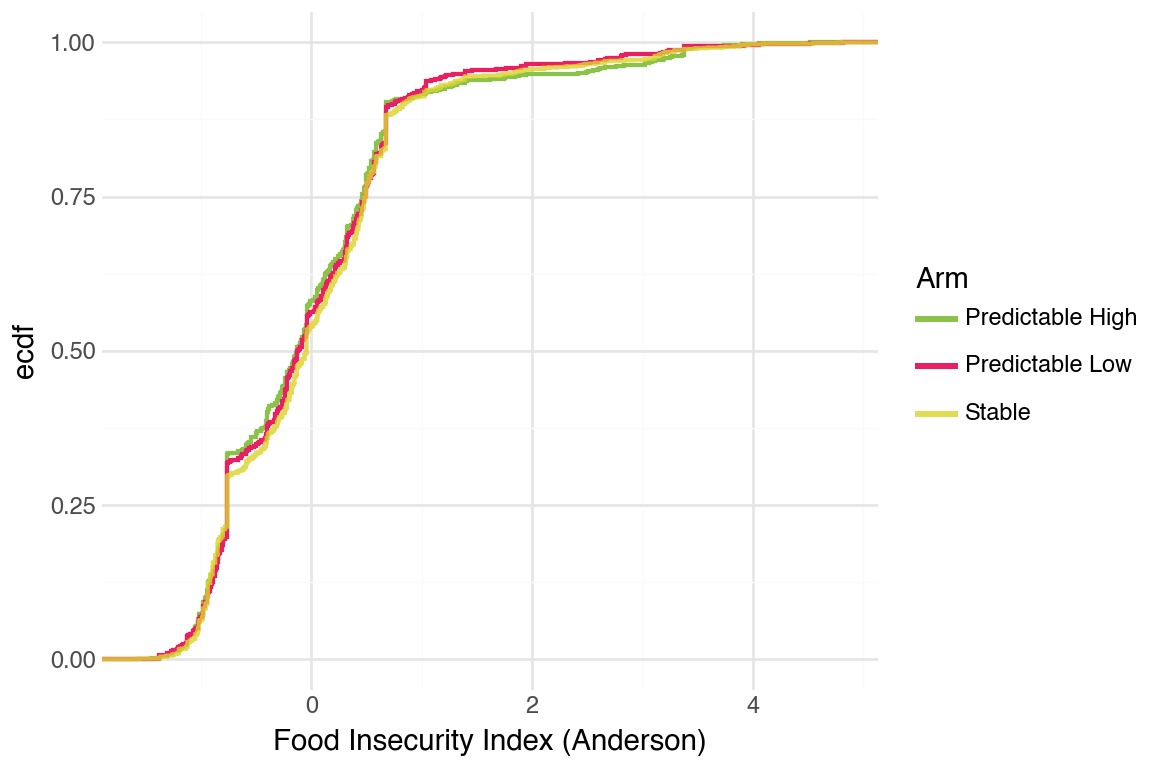
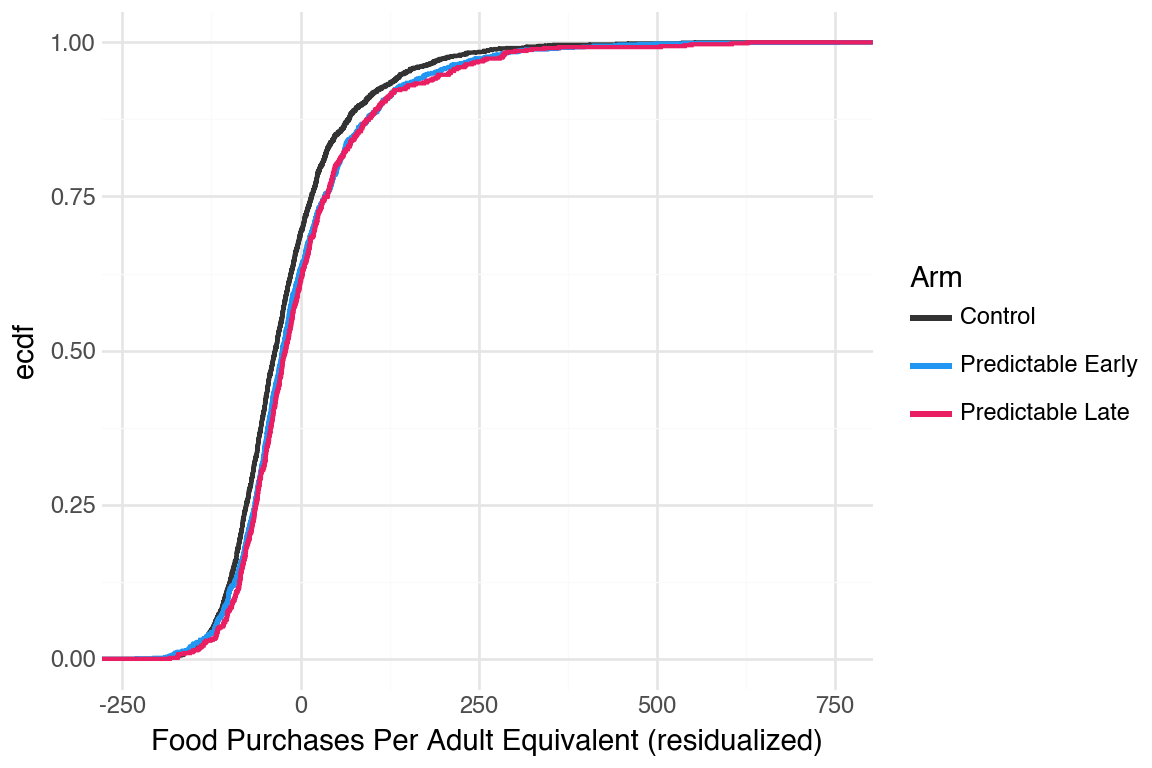
Survey timing doesn’t seem to make much of a difference: late and early predictable look similar in their food purchase decisions
```{python}# Generate a df with the following columns:# - outcome# - arm column# - KS p-value (permutation)# - KS p-value (asymptotic)# - AD p-value (permutation)# - AD p-value (asymptotic)outcomes_to_test = [ "food_purchase_total_99_ae_resid", "fi_index_anderson_resid", "pss4_z_resid", "pswq3_z_resid", "phq2_z_resid", "gad2_z_resid",]arm_columns = ["arm", "arm_split"]records = []for outcome in outcomes_to_test: for arm_col in arm_columns: res = clustered_permutation_test(phone_survey_panel, outcome, arm_col) records.append({ "outcome": outcome, "arm_col": arm_col, "ks_stats": {pair: vals["stat"] for pair, vals in res["ks"].items()}, "ks_p_perm": {pair: vals["p_value"] for pair, vals in res["ks"].items()}, "ks_p_asymp": {pair: vals["p_value_asymptotic"] for pair, vals in res["ks"].items()}, })records_df = pd.DataFrame(records)```
Kolmogorov-Smirnov Test
P-values
The table below display’s two values. The asymptotic p-value is the one we would get from a standard KS test that doesn’t account for clustering. The permutation p-value generated by shuffling treatment labels at the household level and calculating the KS test statistic for each shuffle. The permutation p-value is then the proportion of shuffles where the KS stat is as extreme or more extreme than the observed distribution generated through the shuffle-then-calculate approach.
Code
```{python}# Explode the nested dict columns into one row per arm pairARM_COL_LABELS = {"arm": "3-Arm (S/P/U)", "arm_split": "4-Arm Split"}OUTCOME_LABELS = {f"{k}_resid": v for k, v in outcomes.items()}def sig_stars(p): if p < 0.01: return "***" if p < 0.05: return "**" if p < 0.10: return "*" return ""ks_rows = []for _, row in records_df.iterrows(): for pair, stat in row["ks_stats"].items(): arm_a, arm_b = pair ks_rows.append({ "Outcome": OUTCOME_LABELS.get(row["outcome"], row["outcome"]), "Arm A": arm_a, "Arm B": arm_b, "p (Clustered Perm.)": row["ks_p_perm"][pair], "p (Asymptotic)": row["ks_p_asymp"][pair], })ks_table = pd.DataFrame(ks_rows)ks_table["Sig."] = ks_table["p (Clustered Perm.)"].apply(sig_stars)ks_table = ks_table.reset_index(drop=True)ojs_define(data=ks_table.to_dict(orient="records"))```
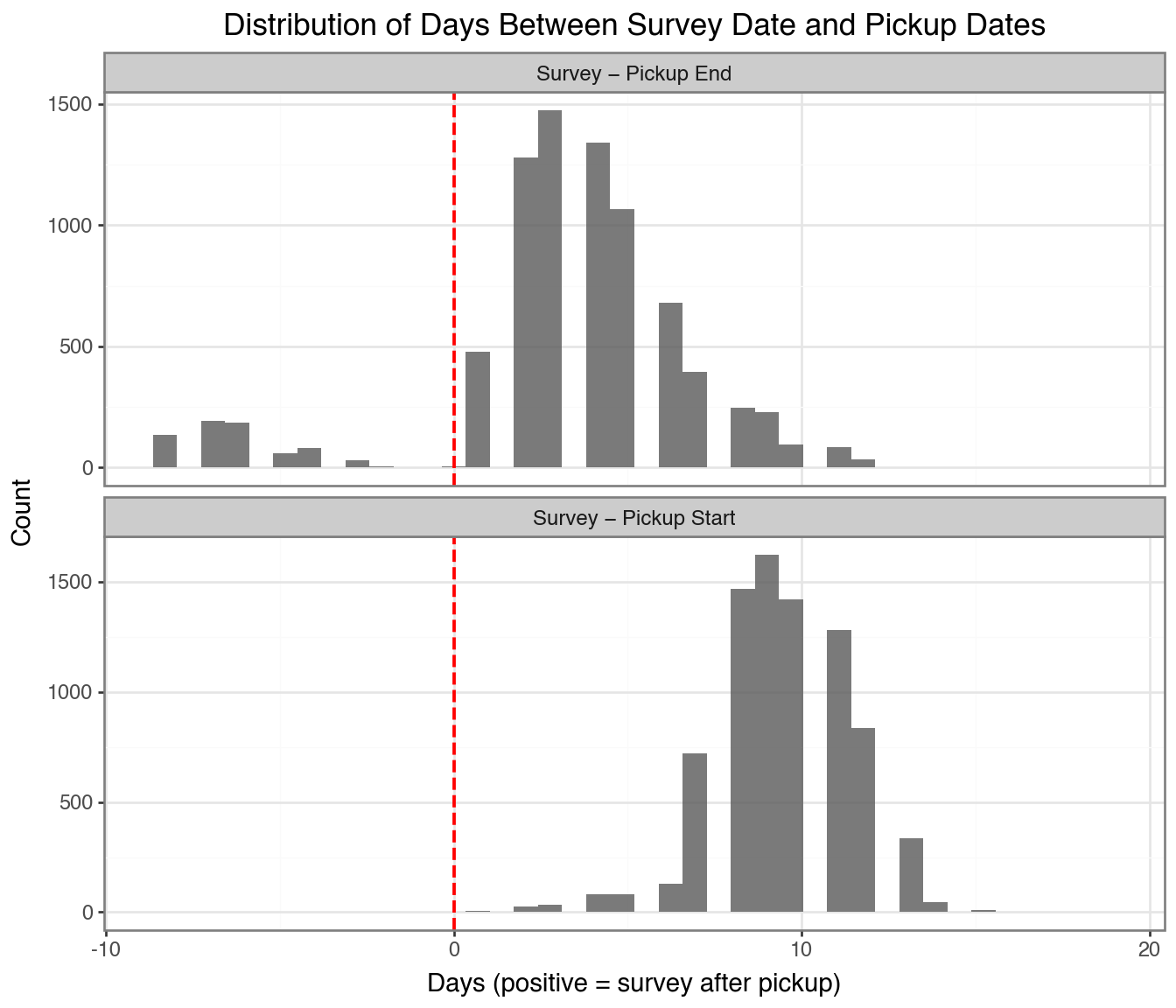
Below is a distribution of the difference in survey and pickup dates (in particular, the last pickup done).
Caution
The negative values indicate people who completed the survey BEFORE pickups were done. All of these happened due to the study pause in periods 3 (mostly) and period 4.
```{python}#| label: survey-pickup-histogramsplot_days = pickup_merged[["days_to_pickup_end", "days_to_pickup_start"]].melt( var_name="measure", value_name="days").dropna()plot_days["measure"] = plot_days["measure"].map({ "days_to_pickup_end": "Survey − Pickup End", "days_to_pickup_start": "Survey − Pickup Start",})( ggplot(plot_days, aes(x="days")) + geom_histogram(bins=40, alpha=0.8) + geom_vline(xintercept=0, linetype="dashed", color="red", size=0.8) + facet_wrap("measure", ncol=1, scales="free_y") + theme_bw() + labs(x="Days (positive = survey after pickup)", y="Count", title="Distribution of Days Between Survey Date and Pickup Dates") + theme(figure_size=(7, 6), strip_text=element_text(size=9)))```
Code
```{python}#| label: predictable-timing-setup# 1. Store median days_to_pickup_endmedian_days_to_pickup_end = pickup_merged["days_to_pickup_end"].median()# 2. Merge days_to_pickup_end onto panel_df (one row per hh_id-period)pickup_days = ( pickup_merged[["hh_id", "period", "days_to_pickup_end"]] .drop_duplicates(subset=["hh_id", "period"]))panel_df = panel_df.merge(pickup_days, on=["hh_id", "period"], how="left")# 3. Create arm_predictable:# - "Control" if treatment == 0# - "Predictable Early" if treatment == 2 and days_to_pickup_end <= median# - "Predictable Late" if treatment == 2 and days_to_pickup_end > median# - NaN for all other treatmentsdef _arm_predictable(row): if row["treatment"] == 0: return "Control" elif row["treatment"] == 2: if pd.isna(row["days_to_pickup_end"]): return np.nan return ( "Predictable Early" if row["days_to_pickup_end"] <= median_days_to_pickup_end else "Predictable Late" ) return np.nandef _arm_stable(row): if row["treatment"] == 0: return "Control" elif row["treatment"] == 3: if pd.isna(row["days_to_pickup_end"]): return np.nan return ( "Stable Early" if row["days_to_pickup_end"] <= median_days_to_pickup_end else "Stable Late" ) return np.nanpanel_df["arm_predictable"] = panel_df.apply(_arm_predictable, axis=1)panel_df["arm_stable"] = panel_df.apply(_arm_stable, axis=1)panel_df["arm_predictable"] = pd.Categorical( panel_df["arm_predictable"], categories=["Control", "Predictable Early", "Predictable Late"],)panel_df["arm_stable"] = pd.Categorical( panel_df["arm_stable"], categories=["Control", "Stable Early", "Stable Late"],)# Subset: phone survey periods only, drop rows with no arm assignmentpredictable_timing_df = panel_df[ (panel_df["period"] > 0) & (panel_df["period"] < 6) & panel_df["arm_predictable"].notna()].copy()stable_timing_df = panel_df[ (panel_df["period"] > 0) & (panel_df["period"] < 6) & panel_df["arm_stable"].notna()].copy()```
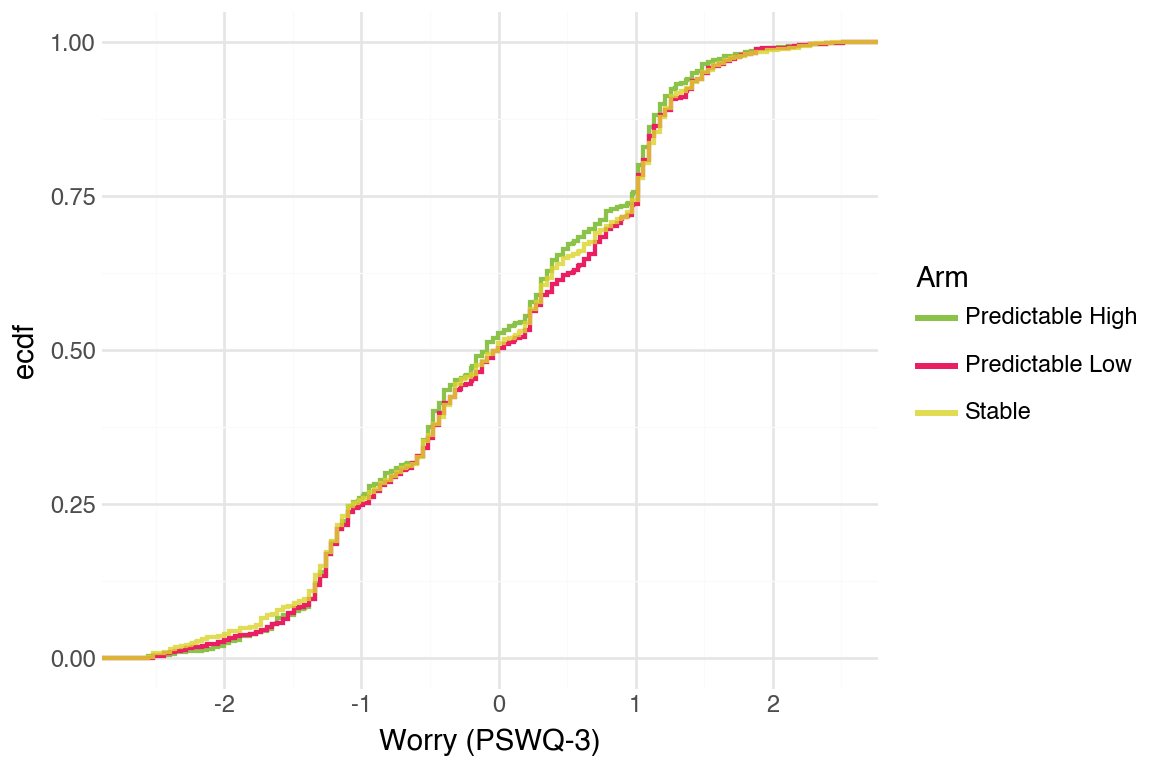
Restricting to the predictable arm, let us see if it makes a difference
Note
Median date used to split predictable arm is 4 days. It is done at the period level so people could switch in and out of the below/above median split over time.